前言
初次了解“设计”,是在大学的图书馆无意翻到的《设计模式:可复用面向对象软件的基础》,那时候只是初略的翻翻,并没有觉得有何特别。再到后来工作几年,参与过一些系统设计,扒过一些优秀的框架,写过一些代码,读过一些书籍和文章之后,对设计有了一些了解。在此分享下自己的记录和理解,也欢迎一起交流。
目录如下
- 一些概念:设计、模型、原则、模式、规范
- 架构设计:从宏观的角度设计
- 面向对象设计:从微观的角度设计
- 领域驱动设计:从业务的角度补充
- 总结
一些概念
是什么
作为一名程序员,我们都知道“设计”是软件开发中的一个步骤(设计先行)。但软件设计到底是什么,可能会存在不同的理解:
- 设计就是讨论要用什么技术实现功能;
- 设计就是要考虑选择哪些框架和中间件;
- 设计就是设计模式;
- 设计就是 Controller、Service 加 Model;
那软件设计到底是什么?从wiki上的一段定义来看
Software design is the process by which an agent creates a specification of a software artifact intended to accomplish goals, using a set of primitive components and subject to constraints.[1] Software design may refer to either “all the activity involved in conceptualizing, framing, implementing, commissioning, and ultimately modifying complex systems” or “the activity following requirements specification and before programming, as … [in] a stylized software engineering process.”[2]
Software design usually involves problem-solving and planning a software solution. This includes both a low-level component and algorithm design and a high-level, architecture design.
软件设计是一个过程,通过该过程,代理使用一组原始组件并受约束来创建用于实现目标的软件工件的规范。软件设计可以是指“涉及概念化、框架化、实施、调试和最终修改复杂系统的所有活动”或“遵循需求规范并在编程之前的活动”
软件设计通常涉及解决问题和规划软件解决方案。这包括低级组件和算法设计以及高级架构设计。简单来说, 软件设计是要在问题和解决方案架设一座桥梁,好的设计要更接近问题

区别于解决简单的问题,软件的开发往往是一项长期的工作,会有许多人参与其中。在这种情况下,就需要建立起一个统一的结构,以便于所有人都能有一个共同的理解。这就如同建筑中的图纸,懂建筑的人看了之后,就会产生一个统一的认识。
模型
在软件的开发过程中,这种统一的结构就是模型(也可以理解为抽象),而软件设计就是要根据问题分析、抽象出一套模型,再根据模型设计、抽象、开发实现对应的软件系统。

模型可以是业务的各种实体,各种服务类,也可以是各种组件、框架。 模型的粒度可大可小。如果把模型理解为一个一个的类,这就是小的模型。也可以把整个系统当作一个整体来理解,这就是大的模型。例如常见的计算机模型,冯诺伊曼模型,计算机网络模型,OSI model,IO模型,JMM内存模型,模型一直都在,只是你没有发现它。 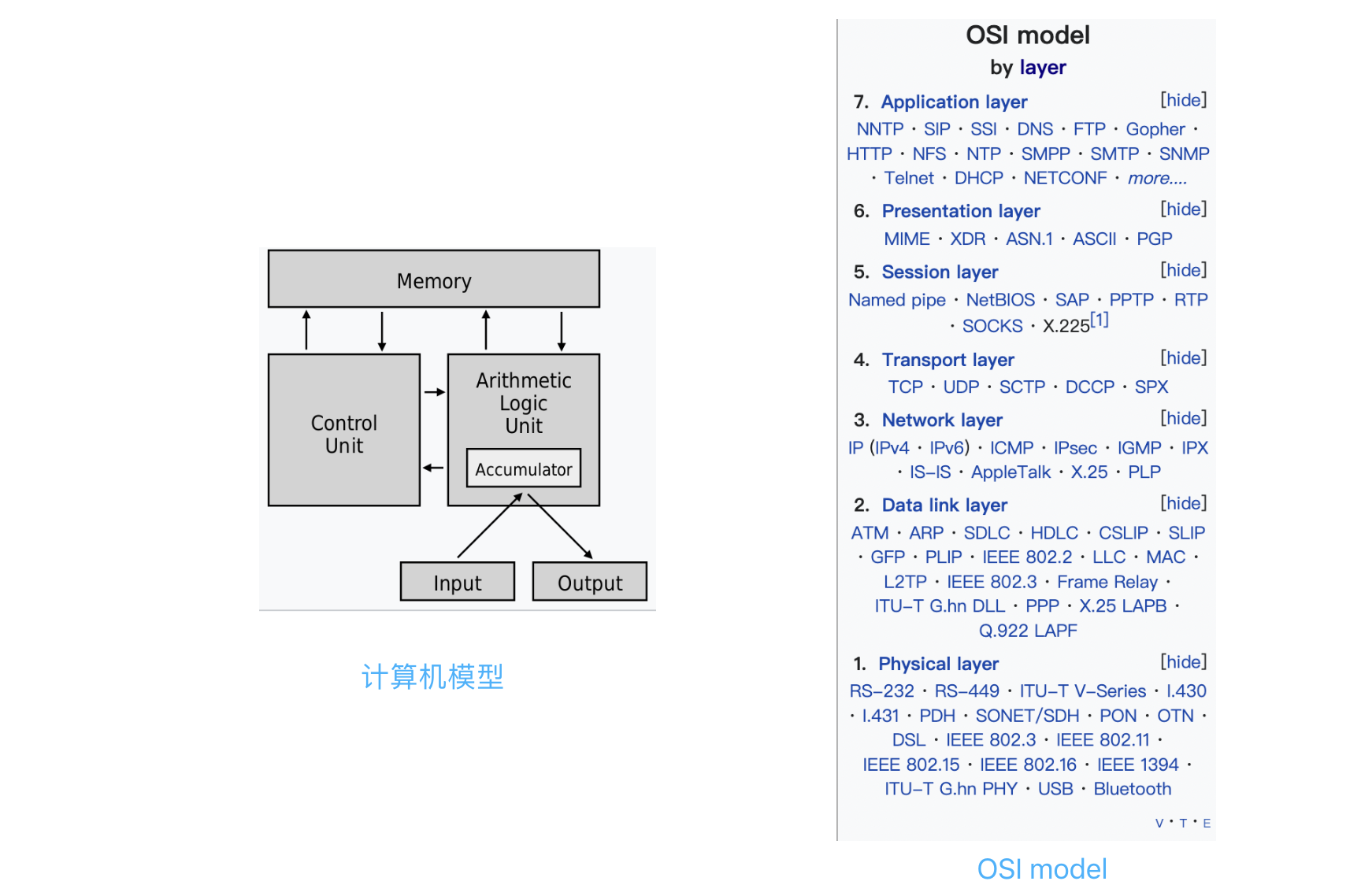
那么怎么建立模型、评判模型的好坏就成了一个问题。
建立模型
编程语言的发展
编程语言的发展可以分为几个阶段,面向机器、面向过程( 数据 )、面向对象
远在1949 年,随着第一台可存储程序的计算机的发明而出现,程序员终于可以写代码了,这个阶段计算机指令的二进制编码,早期的程序员发现记忆计算机指令的二进制编码非常浪费时间,于是他们发明了汇编语言,这阶段其实本质都是面向机器编程。
随着计算机技术的不断发展和计算机的普及,为了更高效地进行编程,应该采用一种对程序员更加友好的编程方式,一种更接近人类语言的编程语言,于是各种各样的高级编程语言出现了。Fortran、C ( Unix 操作系统就使用c语言写的 ),由于这些语言关注逻辑处理过程,所以也被称作面向过程的编程语言(结构化编程,模块)。
面向过程的复杂性随着软件规模的膨胀以更快的速度膨胀,许多软件开发失控,形成了软件危机。软件危机使人们开始重新审视软件编程这件事情的本质,除了一部分科学计算或者其他特定目的的软件,大部分的软件是为了解决现实世界的问题,企业的库存管理、银行的账务处理等等。所以软件编程这件事情应该关注的重点是客观世界的事物本身,向对象的编程语言应运而生( java 、C++ )。
随着计算机性能的不断增强,例如大数据,人工智能以及移动互联网的发展,面向数据的编程需求越来越多,能够更好迎合这一需求的编程模型开始得到青睐,比如函数式编程。
另外,互联网应用对计算资源需求的不断增加,如何更好地利用 CPU 的多核以及分布式集群的多服务器特性,软件编程越来越多需要考虑机器本身,反应式编程也得到越来越多的关注。
从编程语言的发展中我们可以得到建模的一些启示。
数据建模
按照面向机器和数据的思想,计算机就是处理数据计算( 涉及的数据结构 )、存储( 数据存储在硬盘,数据库 )、输入、输出。在软件行业发展的早期,计算方面处理主要是围绕数据,数据结构像堆、栈、链表、树、图等构建与领域无关的模型。存储方面则是数据根据需要对数据库表进行增删改查,这种思路实际上是一种结构化编程的思路。
对象建模
为了应对软件复杂度膨胀,引入了对象的概念,对象和数据结构两者的区别之一就在于对数据的操作是主动还是被动——对象是主动操作数据,而数据结构的数据是被动操作。那么是否使用面向对象的编程语言进行编程,就是面向对象的思想了。
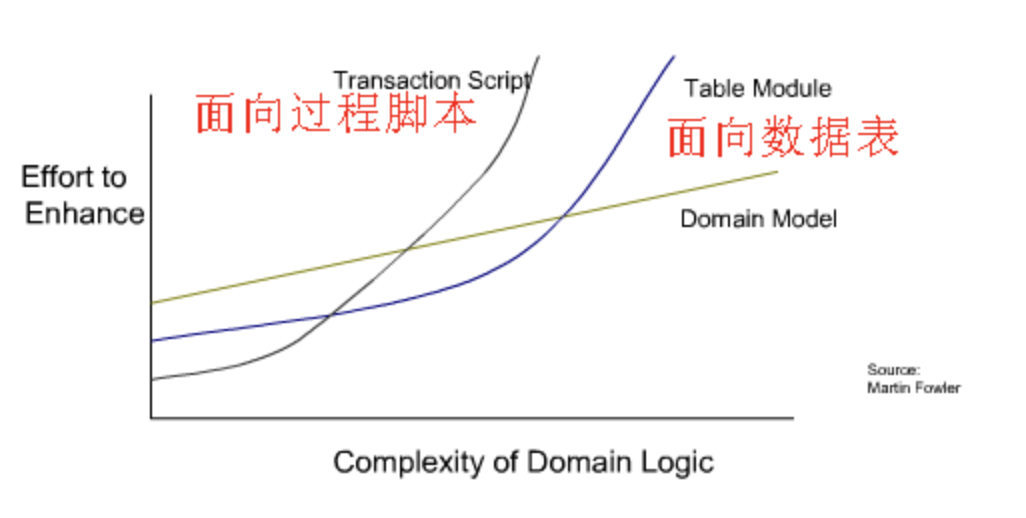
可能未必,例如,目前企业级应用开发中,业务逻辑的组织方式主要是事务脚本模式。事务脚本模式典型的就是 Controller→Service→Dao 这样的程序设计模式。Controller 封装用户请求,根据请求参数构造一些数据对象调用 Service,Service 里面包含大量的业务逻辑代码,完成对数据的处理,期间可能需要通过 Dao 从数据库中获取数据,或者将数据写入数据库中。
由于事务脚本模式中,Service、Dao 这些对象只有方法,没有数值成员变量,而方法调用时传递的数值对象没有方法( 或者只有一些 getter、setter 方法 ),因此事务脚本又被称作贫血模型。
这两种做法本质上没什么太大的区别,都是以数据为中心,以数据库ER设计作驱动。分层架构在这种开发模式下,可以理解为是对数据移动、处理和实现的过程。在业务需求不复杂的年代,围绕数据做文章的做法还能满足开发的要求,但随着软件日益深入到人们日常工作和生活中,软件变得越来越复杂,这种做法就越发显得笨拙了。这个时候就该ddd出场了。
业务建模
领域模型是合并了行为和数据的领域的对象模型。通过领域模型对象的交互完成业务逻辑的实现,也就是说,设计好了领域模型对象,也就设计好了业务逻辑实现。和事务脚本被称作贫血模型相对应的,领域模型也被称为充血模型。领域驱动设计,使用战略设计划分界限上下文,识别核心领域,统一语言。使用战术设计指导聚合根设计,识别实体,值对象。DDD早在随着微服务的浪潮,ddd也大放异彩。
建模工具
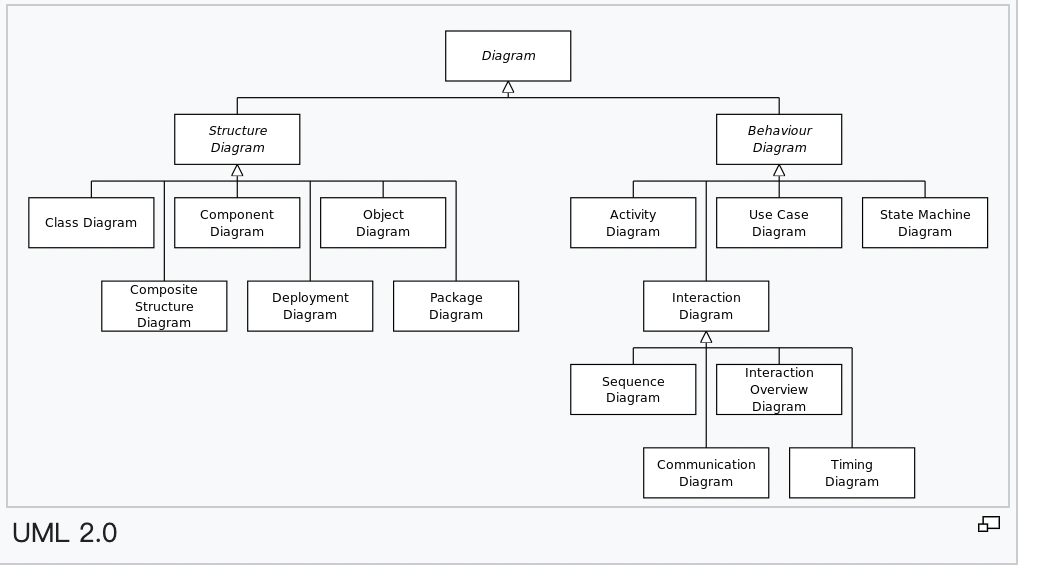
在实践中,通常用来进行软件建模画图的工具是 UML,统一建模语言。UML 包含的软件模型有 10 种,其中常用的有 7 种:类图、序列图、组件图、部署图、用例图、状态图和活动图。
原则
一个模型的好坏我们怎么去评价,或者有什么要求。我们平时常说的高内聚、低耦合( 是软件工程中的概念,是判断设计好坏的标准,主要是面向对象的设计,主要是看类的内聚性是否高,耦合度是否低 )其实是对模型的要求。同时好的模型应该是分层的,例如OSI model的分层,操作系统的分层。符合这些要求的模型,能够有效地隐藏细节,让人理解起来也更容易,甚至还可以在上面继续扩展。
在unix编程艺术中的模块化原则中,给出的建议是从封装、正交性和紧凑性、分层这些方面去设计。当然除了模块化原则,在unix编程艺术中,还列举了很多的原则
- 模块原则:使用简洁的接口拼合简单的部件
- 清晰原则:清晰生于机巧
- 组合原则:设计时考虑拼接组合
- 分离原则:策略同机制分离,接口同引擎分离
- 简洁原则:设计要简洁,复杂度能低则低
- 吝啬原则:除非却无他法,不要编写庞大的程序
- 透明性原则:设计要可见,以便审查和调试
- 健壮原则:健壮源于透明与简洁
- 表示原则:把知识叠入数据以求逻辑质朴而健壮
- 通俗原则:接口设计避免标新立异
- 缄默原则:如果一个程序没什么好说的,就沉默
- 补救原则:出现异常时,马上退出并给出足够多的错误信息
- 经济原则:宁花机器一分,不花程序员一秒
- 生成原则:避免手工hack,尽量编写程序去生成程序
- 优化原则:雕琢前要先有圆形,跑之前先学会走
- 多样性原则:绝不相信所谓”不二法门“的断言
- 扩展原则:设计着眼未来,未来总比预想来的快
这些原则思想,在架构设计、代码设计都有体现。更多原则相关可以阅读这篇文章
所有的这些都在强调kiss ( KEEP IT SIMPLE , STUPID ) 原则,”简单原则”,尽量用简单的方法解决问题,是”Unix哲学”的根本原则。除了kiss原则,还有YAGNI ( You aren‘t gonna nedd it ) 以及DRY ( Dont repeat yourself ) 原则也是比较常见的。面向对象中也有许多经典原则SOLID ( 这个我们在下面再讲 )
模式
当我们在解决一个问题的时候,一般不会发明一种和已有解决方案完全不同的方案来处理这个问题。通常会想起已解决过的相似问题,并重用其解法精华来解决新问题。建筑领域给出的“模式”的定义是,每个模式是一条由三部分组成的规则,它表示一个特定环境、一个问题和一个解决方案之间的关系。这种同时考虑问题、求解方案的,在很多领域都是共同的,建筑学、金融、软件工程中领域也是如此。
所谓“模式”,就是一套反复被人使用或验证过的方法论。从抽象或者更宏观的角度上看,架构设计有其模式,常见的MVC分层、主从、事件驱动、分布式、微服务等。从代码实践角度看,面向对象的有其对应的设计模式,GOF23。(有人专门写了面向模式的软件架构,Pattern-oriented software architecture)
规范
如果说,软件设计要构建出一套模型,这还是比较直观好理解的。因为模型通常可以直接体现在代码中。但软件设计的另一部分——规范,就常常会被忽略。规范,就是限定了什么样的需求应该以怎样的方式去完成,限定了模型的边界和范围。
例如我们可以看到很多框架、软件的实现,都是实现了相关的规范。像我们比较熟悉的java
- java语言有java语言规范
- java虚拟机实现了Spec-Java-Virtual-Machine规范
- 虚拟机中的内存模型实现了Spec-JSR133规范
- 数据库驱动有JDBC驱动
- 服务请求也有servlet规范
这些规范其实都来自jsr,即Java Specification Requests.可以分为两类,一种是java se,se是标准 。一种是java ee,ee是面向企业的,比较熟悉的EJB(Enterprise JavaBean) 是J2EE的一种规范,其中包括了JDBC、JNDI、RMI、JMS、JTA,设计目标与核心应用是部署分布式应用程序,也就是后来的spring框架。
当然除了java,其他像数据库(SQL99、SQL03)、网络(IETF规范)等都有其对应的规范。模型与规范,二者相辅相成。一个项目最初建立起的模型,往往是要符合一定规范的,而规范的制定也有赖于模型。
架构设计
接下来我们从宏观的架构设计,来好好聊聊“设计”
架构到底是指什么
对于技术人员来说,“架构”是一个再常见不过的词了,新员工培训的系统架构,参与架构设计评审,学习业界开源系统的架构。虽然“架构”这个词很常见,但如果深究一下,“架构”到底是指什么,可能大部分人就搞不清楚了。给不出一个具体的定义。
wiki中给出的定义是软件架构是有关软件整体结构与组件的抽象描述,用于指导大型软件系统各个方面的设计。软件架构会包括软件组件、组件之间的关系,组件特性以及组件间关系的特性。
这里比较容易混淆的其实有几个概念
系统与子系统 ,一个系统的架构,只包括顶层这一个层级的架构,而不包括下属子系统层级的架构
模块与组件 ,模块(业务,职责分离)和组件(物理部署,单元复用)都是系统的组成部分,只是从不同的角度拆分系统而已
架构与框架,架是一整套开发规范,架构是某一套开发规范下的具体落地方案,包括各个模块之间的组合关系以及它们协同起来完成功能的运作规则
可能到这里还是感觉挺抽象,那么回想下,我们都是怎么了解、介绍一个系统的。首先浮现在脑海的是一张张的架构图。
架构图
4+1视图
说起架构图,就不能不提UML(类图、序列图、组件图、部署图、用例图、状态图和活动图)和4+1视图(统一建模语言和软件架构的 4+1 模型)
我们还是从它的由来说起。1995 年,Philippe Kruchten 在论文中指出了过去用单一视图描述软件系统架构的问题,并提出了 4+1 视图作为解决方案。
有时,软件架构的问题来源于系统设计者过早地划分软件或者过分地强调软件开发的某一个方面,比如数据工程、运行时效率、开发策略或团队组织。此外,软件架构往往不能解决它的所有“用户”的问题。……作为补救措施,我们建议使用几个并发视图来组织对软件架构的描述,其中每个视图分别解决一组特定的问题。
不同视图之间的关系如下图所示:
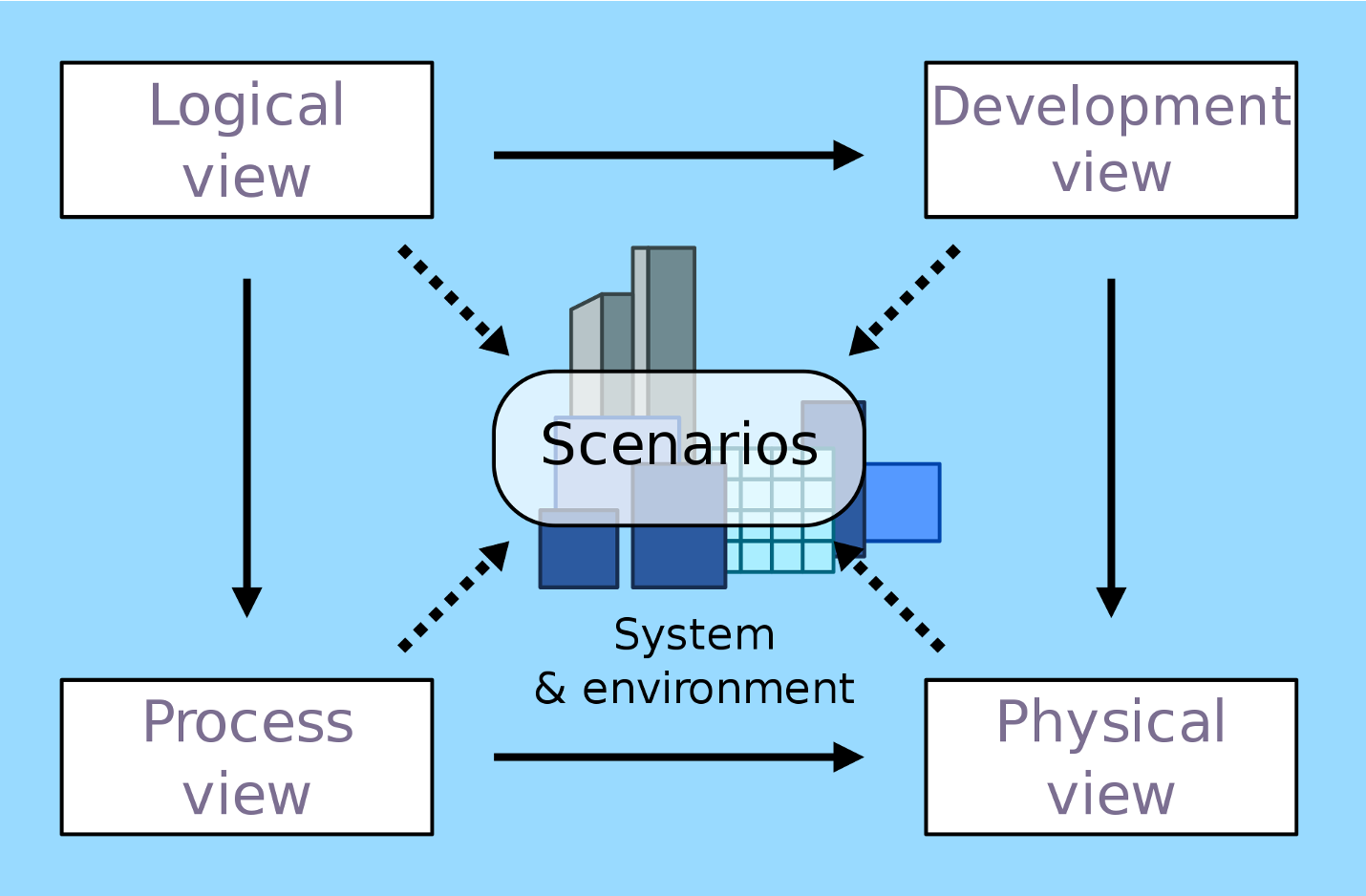
4+1 视图的核心理念是从不同的角度去剖析系统,看看系统的结构是什么样的,具体每个视图的含义是:
逻辑视图:从终端用户角度看系统提供给用户的功能,对应 UML 的 class 和 state diagrams。
处理视图:从动态的角度看系统的处理过程,对应 UML 的 sequence 和 activity diagrams。
开发视图:从程序员角度看系统的逻辑组成,对应 UML 的 package diagrams。
物理视图:从系统工程师角度看系统的物理组成,对应 UML 的 deployment diagrams。
场景视图:从用户角度看系统需要实现的需求,对应 UML 的 use case diagrams。
c4
传统架构图存在以下问题
- 方框或其他形状表示什么意思?
- 虚线 实线 箭头 颜色,比较复杂
- 缺少层级
传统UML的问题在于过于复杂,上手难度大,理解成本高,表现力不够,一张好的架构图不需要多余的文字解释,这里介绍一种简单的方法。
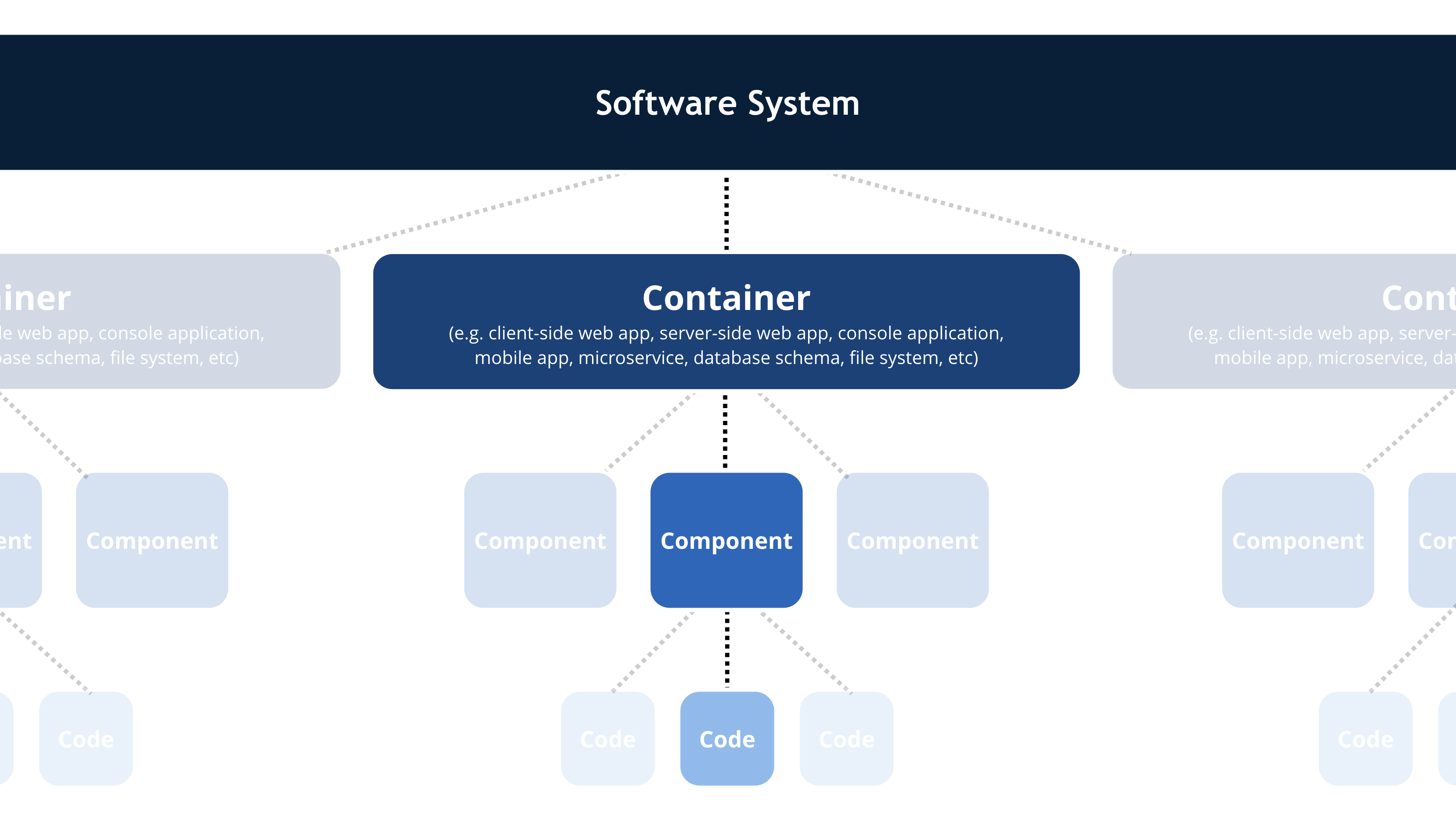
C4 模型是一种易于学习、对开发人员友好的软件架构图表方法。良好的软件架构图有助于软件开发/产品团队内部/外部的沟通、新员工的有效入职、架构审查/评估、风险识别、威胁建模等。(上下文,容器,组件,代码)
类似地图的缩进功能,从一个全局的视角,逐步放大到某一个细节。
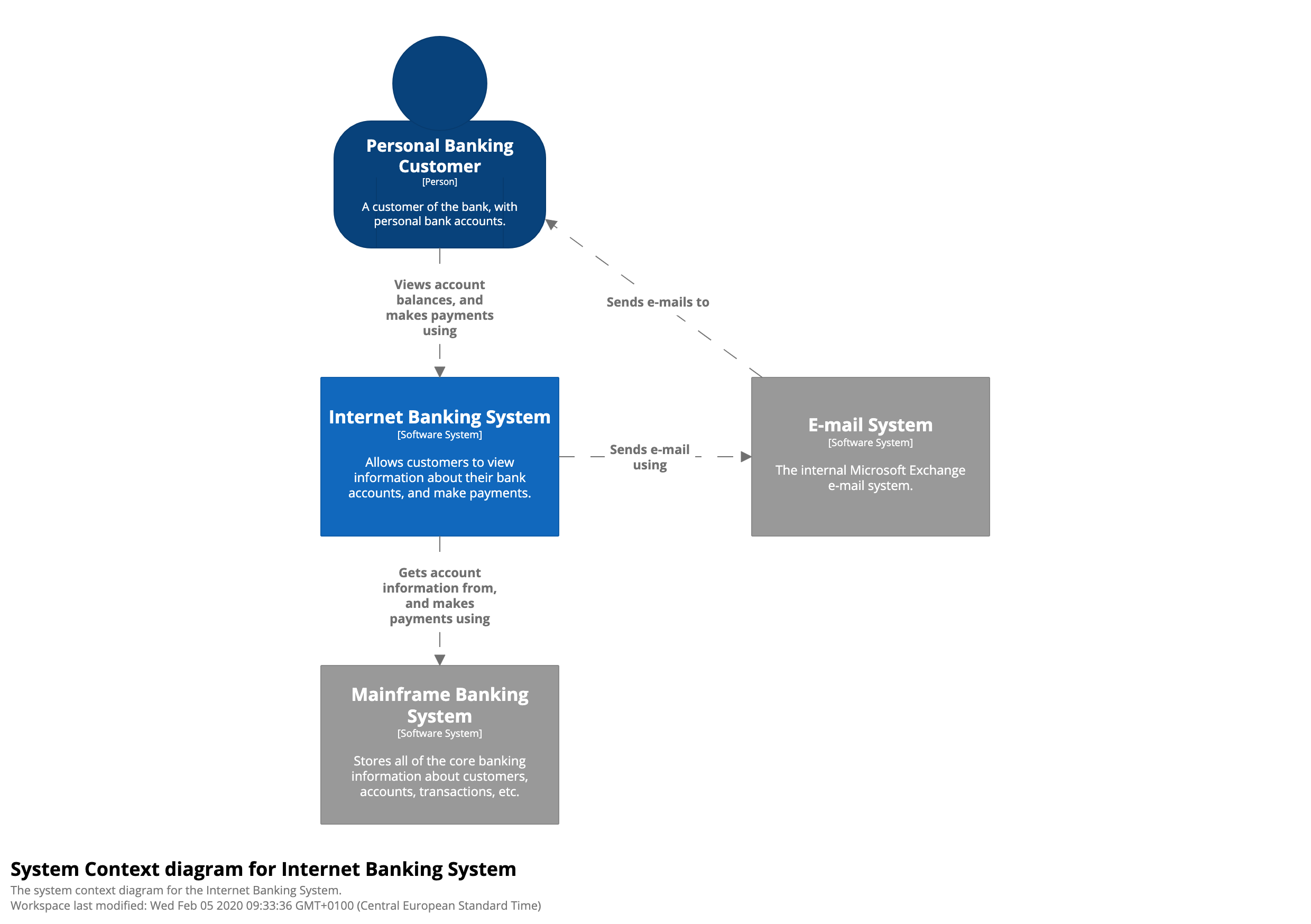
Level 1: System Context diagram
这是一个虚构的网上银行系统的示例系统上下文图。它显示了使用它的人,以及与网上银行系统有关系的其他软件系统。银行的个人客户使用网上银行系统查看有关其银行帐户的信息并进行付款。网上银行系统本身使用银行现有的大型机银行系统来执行此操作,并使用银行现有的电子邮件系统向客户发送电子邮件。
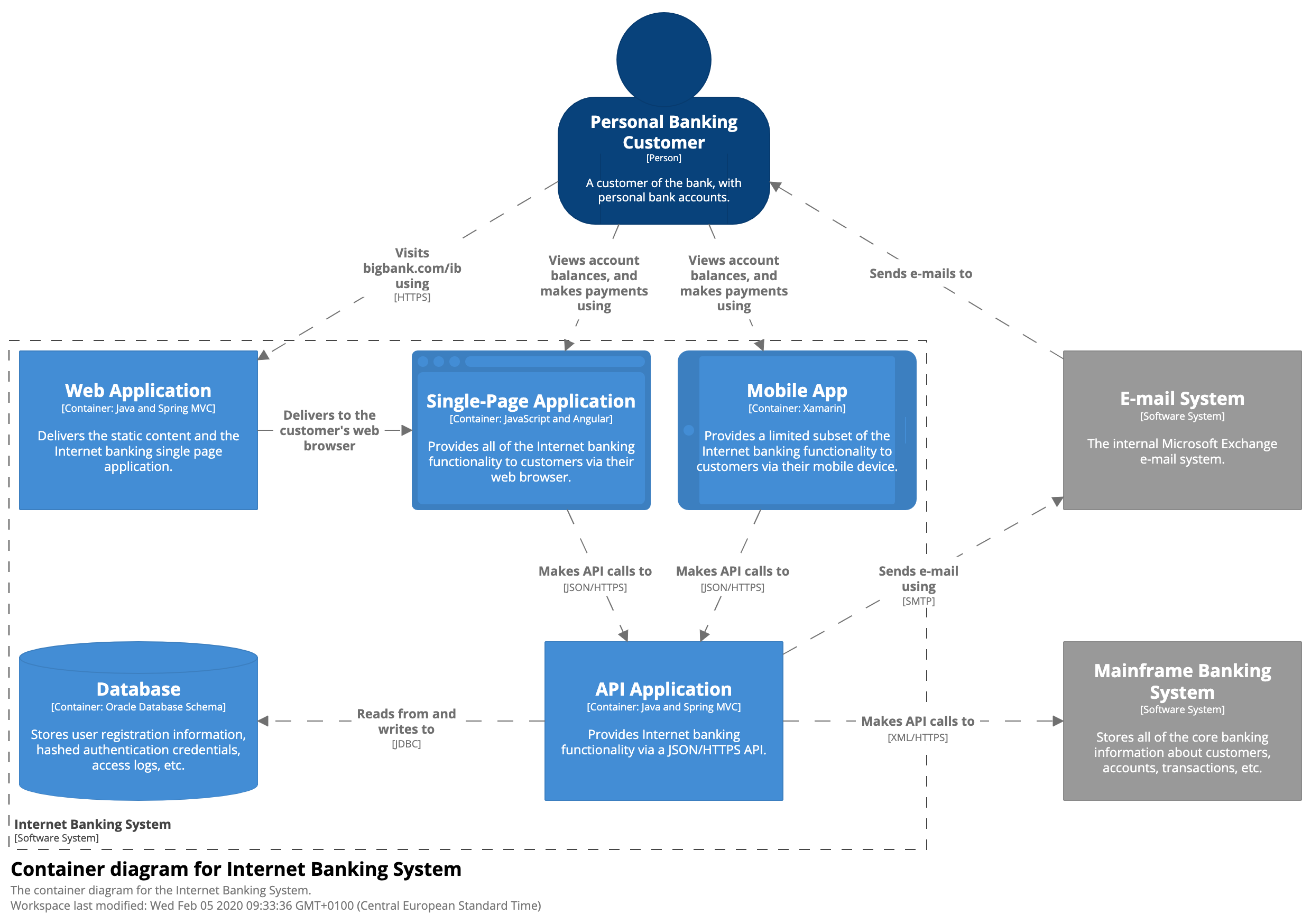
Level 2: Container diagram
这是一个虚构的网上银行系统的示例容器图。它显示网上银行系统(虚线框)由五个容器组成:服务器端 Web 应用程序、单页应用程序、移动应用程序、服务器端 API 应用程序和数据库。Web 应用程序是一个 Java/Spring MVC Web 应用程序,它只提供静态内容(HTML、CSS 和 JavaScript),包括构成单页应用程序的内容。单页应用程序是在客户的网络浏览器中运行的 Angular 应用程序,提供所有网上银行功能。或者,客户可以使用跨平台 Xamarin 移动应用程序来访问网上银行功能的子集。
单页应用程序和移动应用程序都使用 JSON/HTTPS API,该 API 由运行在服务器上的另一个 Java/Spring MVC 应用程序提供。API 应用程序从数据库(关系数据库模式)中获取用户信息。API 应用程序还使用专有的 XML/HTTPS 接口与现有的大型机银行系统进行通信,以获取有关银行帐户的信息或进行交易。如果 API 应用程序需要向客户发送电子邮件,它也会使用现有的电子邮件系统。
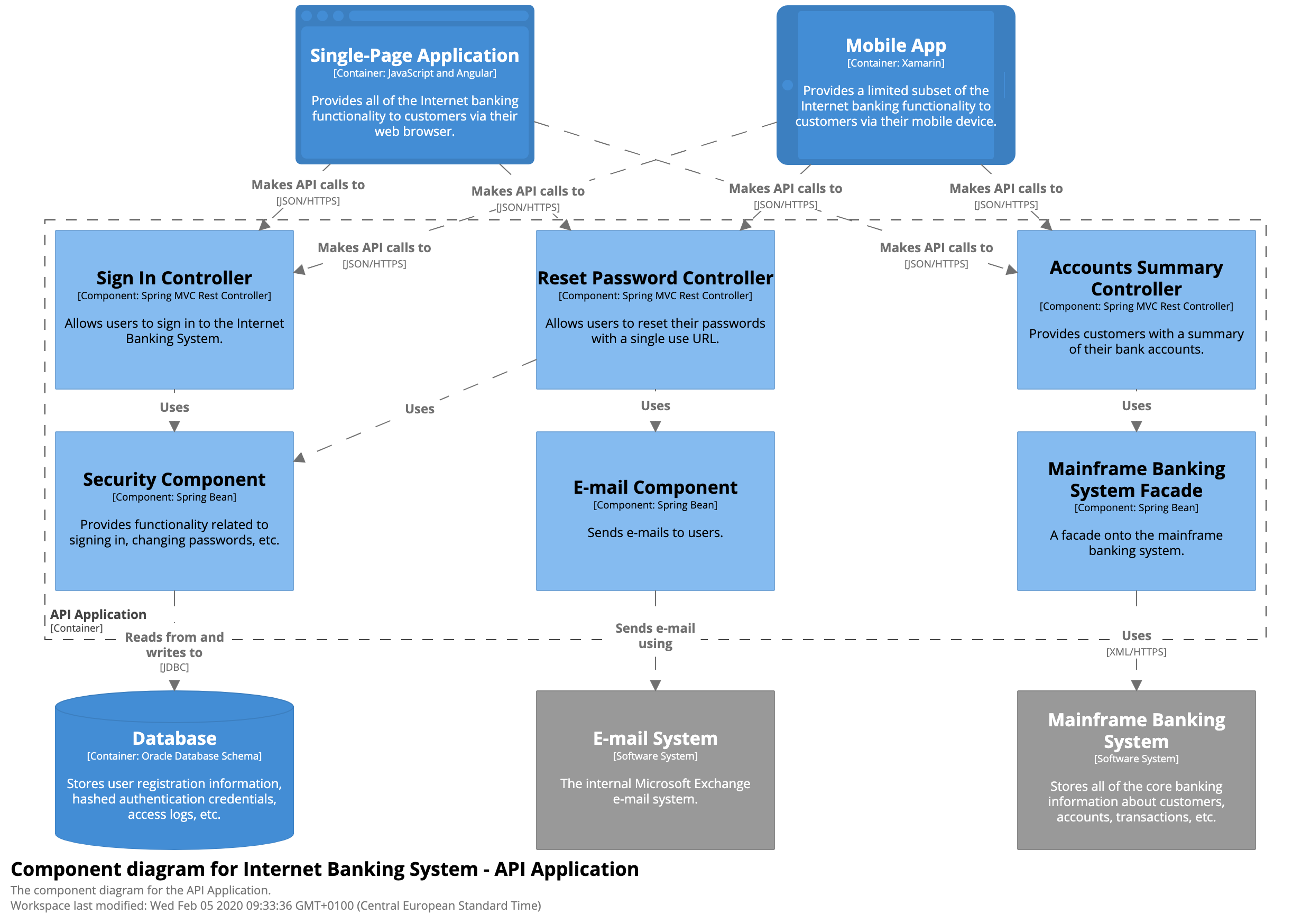
Level 3: Component diagram
这是一个虚构的网上银行系统的示例组件图,显示了 API 应用程序中的一些(而不是全部)组件。在这里,有三个 Spring MVC Rest Controller 为 JSON/HTTPS API 提供访问点,每个控制器随后使用其他组件来访问来自数据库和大型机银行系统的数据,或发送电子邮件。
Level 4: Code
这是一个虚构 Internet 银行系统的示例(和部分)UML 类图,显示了构成 MainframeBankingSystemFacade 组件的代码元素(接口和类)。它表明该组件由许多类组成,实现细节直接反映了代码。
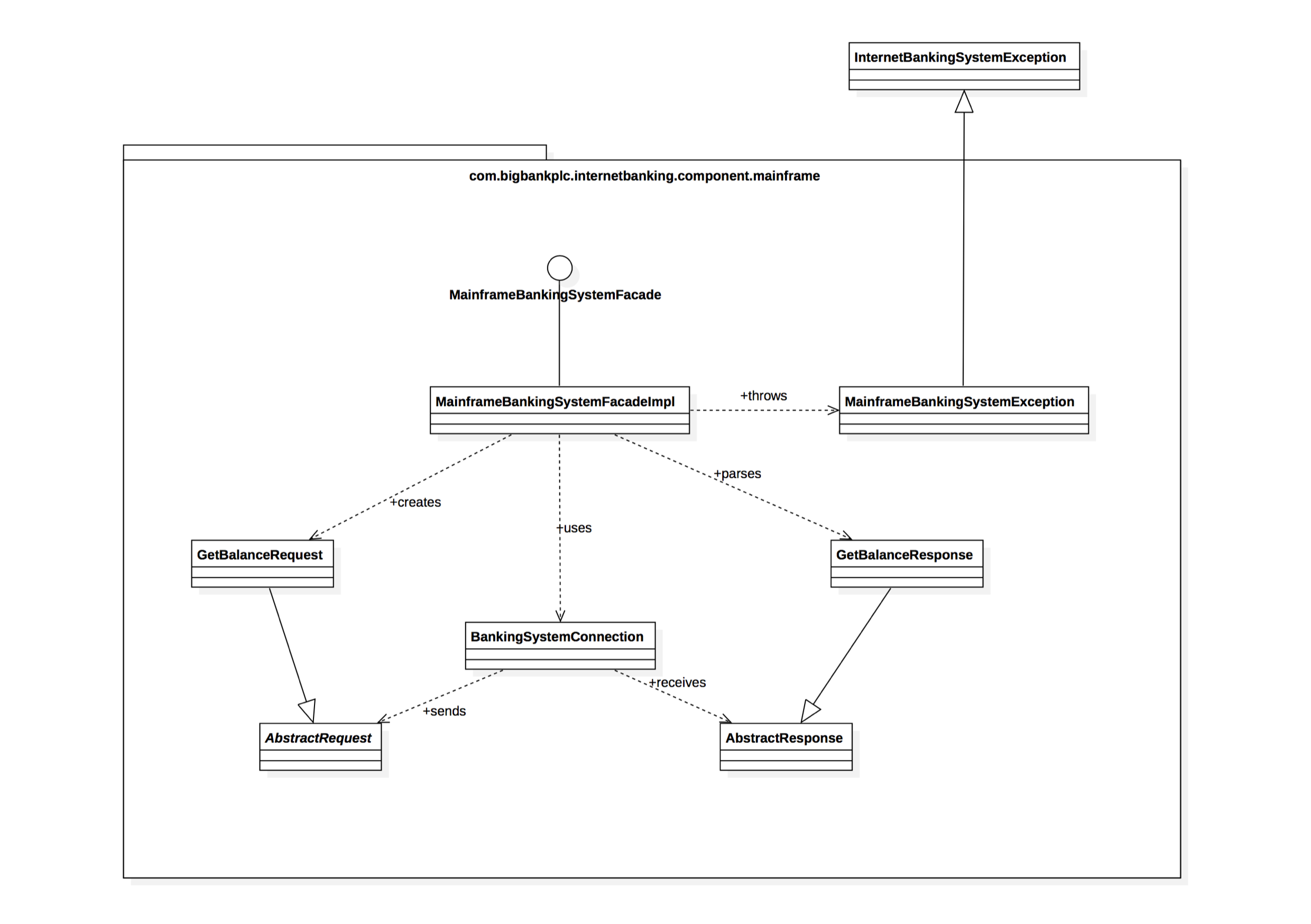
虽然C4简单,但是C4表达能力不足,在《从 0 开始学架构》中提到的4R,或许能解决这个问题。
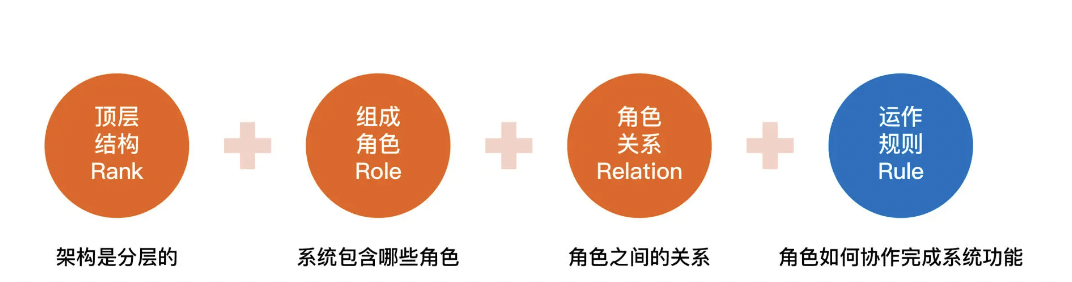
4R
4R指的是,软件架构指软件系统的顶层(Rank)结构,它定义了系统由哪些角色(Role)组成,角色之间的关系(Relation)和运作规则(Rule)。
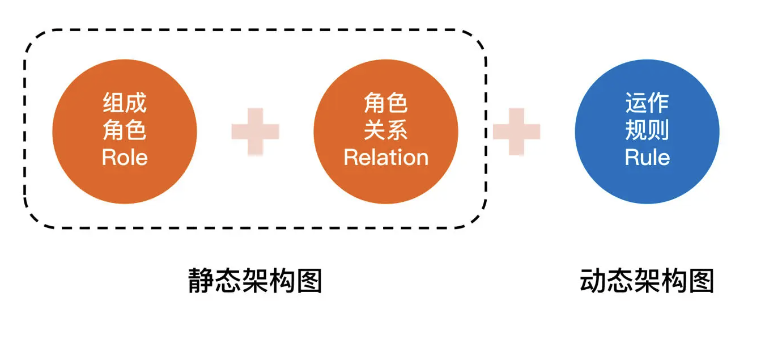
在实际工作中,为了方便理解,Rank、Role 和 Relation 是通过系统架构图来展示的,而 Rule 是通过系统序列图(System Sequence Diagram)来展示的。
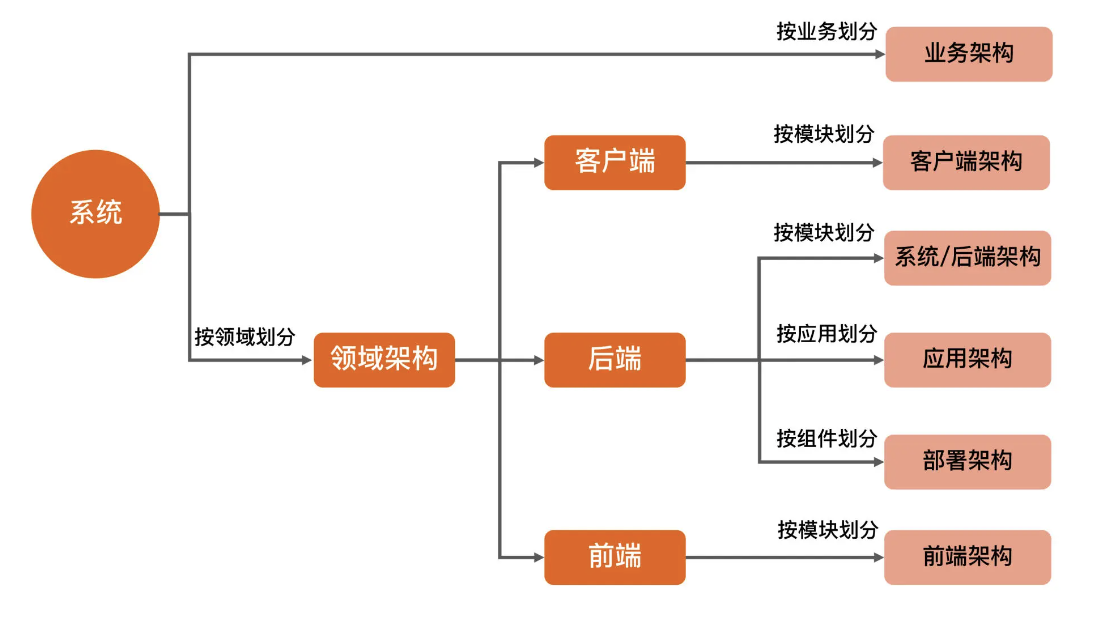
介绍 4+1 视图的时候,我提到过,从不同的角度去剖析系统,就会得到不同的视图。其实按照 4R 架构定义来画架构图也是这样,用不同的方式去划分系统,就会得到不同类型的架构,分别对应不同类型的架构图。常见的类型整理如下:
总之,不管哪种架构图,我们都得先想清楚,受众是谁。到这里,我们对架构应该有所了解,在谈设计之前先来看看架构的演变。
架构设计目的
架构设计的主要目的是为了解决软件系统复杂度带来的问题。通过熟悉和理解需求,识别系统复杂性所在的地方,然后针对这些复杂点进行架构设计。
复杂度的来源
而复杂度的来源主要有以下几个
高性能
一是单台计算机内部为了高性能带来的复杂度;二是多台计算机集群为了高性能带来的复杂度。
高可用
计算(业务的逻辑处理)高可用,存储高可用。高性能增加机器目的在于“扩展”处理性能;高可用增加机器目的在于“冗余”处理单元。
高扩展
提炼出“变化层”和“稳定层”(通过变化层来隔离变化),提炼出“抽象层”和“实现层”(通过实现层来封装变化)。
低成本、安全、规模
- 低成本,低成本本质上是与高性能和高可用冲突的,所以低成本很多时候不会是架构设计的首要目标,而是架构设计的附加约束。
- 安全,一类是功能上的安全,一类是架构上的安全。
- 规模,规模带来复杂度的主要原因就是“量变引起质变”。
- 功能规模大增长,导致系统复杂度,指数级增长。
- 数据越来越多,系统复杂度发生质变,例如数据库的拆分,分库分表的技术。(数据的规模也推动了大数据的发展,Google 发表的三篇大数据相关论文)
原则
那么有什么原则来指导我们进行设计呢?在极客的《从 0 开始学架构》 中作者提到的几个原则觉得挺适用:
- 合适原则
- 简单原则
- 演化原则
合适原则
合适原则宣言:“合适优于业界领先”。
业界领先架构不适用的失败原因有以下几个
- 没那么多人,却想干那么多活,是失败的第一个主要原因。
- 没有那么多积累,却想一步登天,是失败的第二个主要原因。
- 没有那么卓越的业务场景,却幻想灵光一闪成为天才,是失败的第三个主要原因。
真正优秀的架构都是在企业当前人力、条件、业务等各种约束下设计出来的,能够合理地将资源整合在一起并发挥出最大功效,并且能够快速落地
简单原则
简单原则宣言:“简单优于复杂”。
软件领域的复杂性体现在两个方面:
结构的复杂性
- 组件越多,就越有可能其中某个组件出现故障
- 某个组件改动,会影响关联的所有组件
- 定位一个复杂系统中的问题总是比简单系统更加困难
逻辑的复杂性
逻辑复杂的组件,一个典型特征就是单个组件承担了太多的功能,另外一个典型特征就是采用了复杂的算法。复杂算法导致的问题主要是难以理解,进而导致难以实现、难以修改,并且出了问题难以快速解决。
演化原则
演化原则宣言:“演化优于一步到位”。
- 首先,设计出来的架构要满足当时的业务需要。
- 其次,架构要不断地在实际应用过程中迭代,保留优秀的设计,修复有缺陷的设计,改正错误的设计,去掉无用的设计,使得架构逐渐完善。
- 第三,当业务发生变化时,架构要扩展、重构,甚至重写;代码也许会重写,但有价值的经验、教训、逻辑、设计等(类似生物体内的基因)却可以在新架构中延续。
因为很难完美预测所有的业务发展和变化路径,所以应该认真分析当前业务的特点,明确业务面临的主要问题,设计合理的架构,快速落地以满足业务需要,然后在运行过程中不断完善架构,不断随着业务演化架构。
另外关于原则还有类似的可以查看这里,以及解密腾讯海量服务之道也值得参考。
架构演化
我们在之前讨论了编程语言的发展,这里也同样来看下架构的演化,看看我们能从中收获什么。
原始分布式时代:Unix设计哲学
在20 世纪 70 年代末到 80 年代初,计算机科学刚经历了从以大型机为主,到向以微型机为主的蜕变,这个时候的微型计算机系统,通常具有 16 位寻址能力、不足 5MHz(兆赫)时钟频率的处理器和 128KB 左右的内存地址空间,为了突破硬件算力的限制,各个高校、研究机构、软硬件厂商,都开始分头探索,想看看到底能不能使用多台计算机共同协作,来支撑同一套软件系统的运行。这个阶段其实是对分布式架构最原始的探索与研究。而亲身经历过那个年代的计算机科学家、IBM 院士凯尔 · 布朗(Kyle Brown),在事后曾经评价道,“这次尝试最大的收获就是对 RPC、DFS 等概念的开创,以及得到了一个价值千金的教训:某个功能能够进行分布式,并不意味着它就应该进行分布式,强行追求透明的分布式操作,只会自寻苦果”。
在当时计算机科学面前,有两条通往更大规模软件系统的道路,一条路是尽快提升单机的处理能力,以避免分布式的种种问题;另一条路是找到更完美的解决方案,来应对如何构筑分布式系统的问题。(服务的发现、跟踪、通讯、容错、隔离、配置、传输、数据一致性和编码复杂度等方面的问题)
在 20 世纪 80 年代,正是摩尔定律开始稳定发挥作用的黄金时期,微型计算机的性能以每两年就增长一倍的惊人速度在提升,硬件算力束缚软件规模的链条,很快就松动了,我们用单台或者几台计算机,就可以作为服务器来支撑大型信息系统的运作了,信息系统进入了单体时代,而且在未来很长的一段时间内,单体系统都将是软件架构的主流。
不过尽管如此,对于另外一条路径,也就是对分布式计算、远程服务调用的探索,开发者们也从没有中断过。才有了后面的SOA、微服务。
单体架构:最广泛的架构风格
单体架构是绝大部分软件开发者都学习和实践过的一种软件架构,很多介绍微服务的图书和技术资料中,也常常会把这种架构形式的应用称作“巨石系统”(Monolithic Application)。在整个软件架构演进的历史进程里,单体架构是出现时间最早、应用范围最广、使用人数最多、统治历史最长的一种架构风格。
落后架构
那在剖析单体架构之前呢,我们有必要先搞清楚对单体架构的两个思维误区,一个是认为,单体架构是落后的系统架构风格,最终会被微服务所取代。
对于小型系统,也就是用单台机器就足以支撑其良好运行的系统来说,这样的单体不仅易于开发、易于测试、易于部署,而且因为各个功能、模块、方法的调用过程,都是在进程内调用的,不会发生进程间通讯,所以程序的运行效率也要比分布式系统更高。所以,当我们在讨论单体系统的缺陷的时候,必须基于软件的性能需求超过了单机,软件的开发人员规模明显超过了“2 Pizza Teams”范畴的前提下,这样才有讨论的价值。
不可拆分
另一个误区是“不可拆分”,难以扩展,所以它才不能支撑起越来越大的软件规模。但它的不可拆分,可能我们的理解也需要弄清楚。
从两个角度来看拆分,纵向角度可拆分,分层架构(Layered Architecture)已经是现在几乎所有的信息系统建设中,都普遍认可、普遍采用的软件设计方法了。无论是单体还是微服务,或者是其他架构风格,都会对代码进行纵向拆分,收到的外部请求会在各层之间,以不同形式的数据结构进行流转传递,在触及到最末端的数据库后依次返回响应。
而在横向角度的“可拆分”上,单体架构也可以支持按照技术、功能、职责等角度,把软件拆分为各种模块,以便重用和团队管理。即使是从横向扩展(Scale Horizontally)的角度来衡量,如果我们要在负载均衡器之后,同时部署若干个单体系统的副本,以达到分摊流量压力的效果,那么基于单体架构,也是轻而易举就可以实现的。单体系统也会做集群部署,也会有服务冗余,也会进行主从热备。
单体系统的真正缺陷实际上并不在于要如何拆分,而在于拆分之后,它会存在隔离与自治能力上的欠缺。
单体作为迄今为止使用人数最多的一种软件架构风格,自身必定是有可取之处的,比如说,易于分层、易于开发、易于部署测试、进程内的高效交互,等等,这些都是单体架构的优点。可是,今天以微服务为代表的分布式架构的呼声如此之高,也同样说明,单体至少在当今的某些领域中存在一些关键性的问题。
SOA架构:成功理论失败实践
在介绍 SOA 架构模式之前,我们先来看三种比较有代表性的服务拆分的架构模式。这些架构是 SOA 演化过程的中间产物,你也可以理解为,它们是 SOA 架构出现的必要前提。
烟囱式架构(Information Silo Architecture)
信息烟囱也被叫做信息孤岛(Information Island),使用这种架构的系统呢,也被称为孤岛式信息系统或者烟囱式信息系统。这种信息系统,完全不会跟其他相关的信息系统之间进行互操作,或者是进行协调工作。
所以,两个不发生交互的信息系统,让它们使用独立的数据库、服务器,就可以完成拆分了。而唯一的问题,也是这个架构模式的致命问题,那就是:企业中真的存在完全不发生交互的部门吗?
微内核架构(Microkernel Architecture)
既然在烟囱式架构中,我们说两个没有业务往来关系的系统,也可能需要共享人员、组织、权限等一些公共的主数据,那就不妨把这些主数据,连同其他可能被各个子系统使用到的公共服务、数据、资源,都集中到一块,成为一个被所有业务系统共同依赖的核心系统(Kernel,也称为 Core System)。这样的话,具体的业务系统就能以插件模块(Plug-in Modules)的形式存在了,就可以为整个系统提供可扩展的、灵活的、天然隔离的功能特性。
不过,微内核架构也有它的局限和使用前提,它会假设系统中各个插件模块之间是互不认识的(不可预知系统会安装哪些模块),这些插件会访问内核中一些公共的资源,但不会发生直接交互。
可是,无论是在企业信息系统还是在互联网,在许多场景中这一假设都不成立。比如说,你要建设一个购物网站,支付子系统和用户子系统是独立的,但当交易发生时,支付子系统可能需要从用户子系统中得到是否是 VIP、银行账号等信息,而用户子系统也可能要从支付子系统中获取交易金额等数据,来维护用户积分。所以,我们必须找到一个办法,它既能拆分出独立的系统,也能让拆分后的子系统之间可以顺畅地互相调用通讯
事件驱动架构(Event-Driven Architecture)
那么,为了能让子系统之间互相通讯,事件驱动架构就应运而生了。这种架构模式的运作方案是,在子系统之间建立一套事件队列管道(Event Queues),来自系统外部的消息将以事件的形式发送到管道中,各个子系统可以从管道里获取自己感兴趣、可以处理的事件消息,也可以为事件新增或者是修改其中的附加信息,甚至还可以自己发布一些新的事件到管道队列中去。这样一来,每一个消息的处理者都是独立的、高度解耦的,但它又能与其他处理者(如果存在该消息处理者的话)通过事件管道来进行互动。
当系统演化至事件驱动架构的时候,且第二条通往大规模软件的路径,也就是仍然在并行发展的远程服务调用,就迎来了 SOAP 协议的诞生。此时“面向服务的架构”(Service Oriented Architecture,SOA),就已经有了登上软件架构舞台所需要的全部前置条件了。
SOA 看可以称之为一套软件架构的基础平台。
那,我们怎么理解“基础平台”这个概念呢?主要是下面几个方面:
- SOA 拥有领导制定技术标准的组织 Open CSA;
- SOA 具有清晰的软件设计的指导原则,比如服务的封装性、自治、松耦合、可重用、可组合、无状态,等 等;SOA 架构明确了采用 SOAP 作为远程调用的协议,依靠 SOAP 协议族(WSDL、UDDI 和一大票 WS-* 协议)来完成服务的发布、发现和治理;
- SOA 架构会利用一个被称为是企业服务总线(Enterprise Service Bus,ESB)的消息管道,来实现各个子系统之间的通讯交互,这就让各个服务间在 ESB 的调度下,不需要相互依赖就可以实现相互通讯,既带来了服务松耦合的好处,也为以后可以进一步实现业务流程编排(Business Process Management,BPM)提供了基础;
- SOA 架构使用了服务数据对象(Service Data Object,SDO)来访问和表示数据,使用服务组件架构(Service Component Architecture,SCA)来定义服务封装的形式和服务运行的容器;
在这一整套成体系、可以互相精密协作的技术组件的支持下,我们从技术可行性的角度来评判的话,SOA 实际上就可以算是成功地解决了分布式环境下,出现的诸如服务注册、发现、隔离、治理等主要技术问题了。
但SOA 架构过于严谨精密的流程与理论,导致了软件开发的全过程,都需要有懂得复杂概念的专业人员才能够驾驭,最本质的原因就是过于严格的规范定义,给架构带来了过度的复杂性,这其实跟当年的EJB(Enterprise JavaBean,企业级 JavaBean)的失败如出一辙。
微服务架构:SOA革命者
“微服务”这个词,并不是直接凭空创造出来的概念。最开始的微服务,可以说是在 SOA 发展的同时被催生出来的产物,就像是 EJB 在推广的过程中,催生出了 Spring 和 Hibernate 框架那样。这一阶段的微服务,是作为 SOA 的一种轻量化的补救方案而被提出来的。
微服务真正崛起是在 2014 年,也就是从 Martin Fowler 和 James Lewis 合写的文章“Microservices: a definition of this new architectural term”里面,第一次了解到微服务的。
这篇文章定义了现代微服务的概念:微服务是一种通过多个小型服务的组合,来构建单个应用的架构风格,这些服务会围绕业务能力而非特定的技术标准来构建。各个服务可以采用不同的编程语言、不同的数据存储技术、运行在不同的进程之中。服务会采取轻量级的通讯机制和自动化的部署机制,来实现通讯与运维。
在这篇论文中,作者还列举出了微服务的九个核心的业务与技术特征
第一,围绕业务能力构建(Organized around Business Capabilities)
第二,分散治理(Decentralized Governance)
第三,通过服务来实现独立自治的组件(Componentization via Services)
第四,产品化思维(Products not Projects)
第五,数据去中心化(Decentralized Data Management)
第六,轻量级通讯机制(Smart Endpoints and Dumb Pipes)
第七,容错性设计(Design for Failure)
第八,演进式设计(Evolutionary Design)
第九,基础设施自动化(Infrastructure Automation)
微服务追求的是更加自由的架构风格,它摒弃了 SOA 中几乎所有可以抛弃的约束和规定,提倡以“实践标准”代替“规范标准”。
可是,如果没有了统一的规范和约束,以前 SOA 解决的那些分布式服务的问题,不又都重新出现了吗?没错,的确如此。服务的注册发现、跟踪治理、负载均衡、故障隔离、认证授权、伸缩扩展、传输通讯、事务处理等问题,在微服务中,都不再会有统一的解决方案。例如,即使我们只讨论 Java 范围内会使用到的微服务,那么光一个服务间通讯的问题,可以列入候选清单的解决方案就有很多很多。比如,RMI(Sun/Oracle)、Thrift(Facebook)、Dubbo(阿里巴巴)、gRPC(Google)、Motan2(新浪)、Finagle(Twitter)、brpc(百度)、Arvo(Hadoop)、JSON-RPC、REST,等等。再来举个例子,光一个服务发现问题,我们可以选择的解决方案就有:Eureka(Netflix)、Consul(HashiCorp)、Nacos(阿里巴巴)、ZooKeeper(Apache)、etcd(CoreOS)、CoreDNS(CNCF),等等。
在微服务时代中,软件研发本身的复杂度应该说是有所降低,一个简单服务,并不见得就会同时面临分布式中所有的问题,也就没有必要背上 SOA 那百宝袋般沉重的技术包袱。微服务架构下,我们需要解决什么问题,就引入什么工具;团队熟悉什么技术,就使用什么框架。此外,像 Spring Cloud 这样的胶水式的全家桶工具集,通过一致的接口、声明和配置,进一步屏蔽了源自于具体工具、框架的复杂性,降低了在不同工具、框架之间切换的成本
后微服务时代:云原生
微服务时代,我们之所以不得不在应用服务层面,而不是基础设施层面去解决这些分布式问题,完全是因为由硬件构成的基础设施,跟不上由软件构成的应用服务的灵活性。这其实是一种无奈之举。
但是随着2017 年 Kubernetes 赢得容器战争的胜利,标志着后微服务时代的到来,开始普遍采用的通过虚拟化(虚拟化技术和容器化技术)的基础设施,去解决分布式架构问题的方案。
针对同一个分布式服务的问题,对比下 Spring Cloud 中提供的应用层面的解决方案,以及 Kubernetes 中提供的基础设施层面的解决方案。
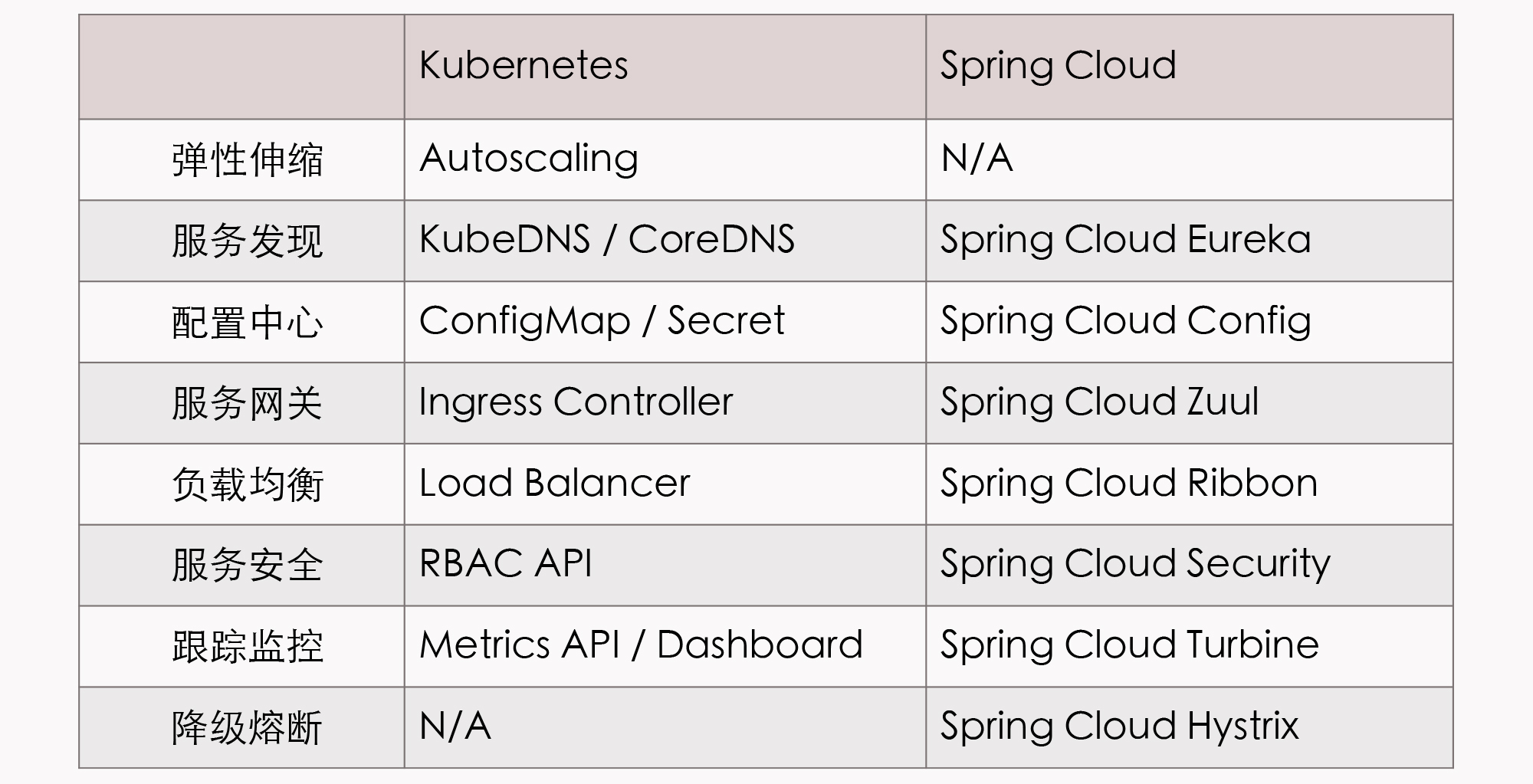
但 Kubernetes 其实并没有完美地解决全部的分布式问题。这里所说的“不完美”的意思是,仅从功能灵活强大这点来看,Kubernetes 反而还不如之前的 Spring Cloud 方案。这是因为有一些问题处于应用系统与基础设施的边缘,我们很难能完全在基础设施的层面中,去精细化地解决掉它们。
为了解决这一类问题,微服务基础设施很快就进行了第二次进化,引入在今天被我们叫做是“服务网格”(Service Mesh)的“边车代理模式”(Sidecar Proxy)。
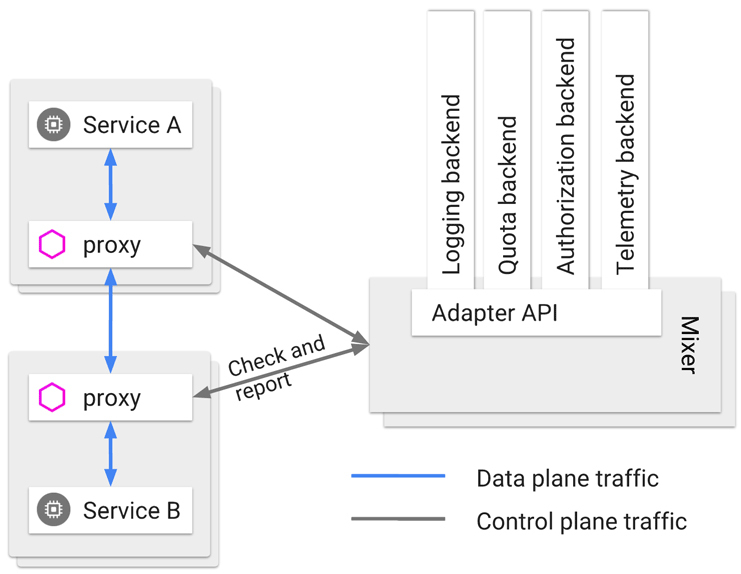
服务网格将会成为微服务之间通讯交互的主流模式,它会把“选择什么通讯协议”“如何做认证授权”之类的技术问题隔离于应用软件之外,取代今天的 Spring Cloud 全家桶中的大部分组件的功能。这是最理想的Smart Endpoints解决方案,微服务只需要考虑业务本身的逻辑就行了,业务与技术完全分离,远程与本地完全透明,这也许这就是分布式架构最好的时代吧。
无服务时代:“不分布式”云端系统的起点
我们都知道,分布式架构出现的最初目的,是要解决单台机器的性能成为整个软件系统的瓶颈的问题。后来随着技术的演进,容错能力、技术异构、职责划分等其他因素,也都成了分布式架构要考虑的问题。但不可否认的是,获得更好的性能,仍然在架构设计中占有非常大的比重。
但分布式架构也会引入一些新问题(比如服务的安全、容错,分布式事务的一致性),因此对软件开发这件事儿来说,不去做分布式无疑是最简单的。如果单台服务器的性能可以是无限的,那架构演进的结果,肯定会跟今天不一样。不管是分布式和容器化,还是微服务,恐怕都未必会出现了,最起码不会是今天的模样。
当然了,绝对意义上的无限性能肯定是不存在的,但相对意义上的无限性能其实已经实现了,云计算的成功落地就可以说明这一点。对基于云计算的软件系统来说,无论用户有多少、逻辑如何复杂,AWS、阿里云等云服务提供商都能在算力上满足系统对性能的需求,只要你能为这种无限的性能支付得起对应的代价。
“无服务”(Serverless)涉及了后端设施(Backend)和函数(Function)两块内容。
后端设施是指数据库、消息队列、日志、存储等这一类用于支撑业务逻辑运行,但本身无业务含义的技术组件。这些后端设施都运行在云中,也就是无服务中的“后端即服务”(Backend as a Service,BaaS)。
函数指的就是业务逻辑代码。这里函数的概念与粒度,都已经和程序编码角度的函数非常接近了,区别就在于,无服务中的函数运行在云端,不必考虑算力问题和容量规划(从技术角度可以不考虑,但从计费的角度来看,你还是要掂量一下自己的钱包够不够用),也就是无服务中的“函数即服务”(Function as a Service,FaaS)。
无服务的愿景是让开发者只需要纯粹地关注业务:
- 一是,不用考虑技术组件,因为后端的技术组件是现成的,可以直接取用,没有采购、版权和选型的烦恼;
- 二是,不需要考虑如何部署,因为部署过程完全是托管到云端的,由云端自动完成;
- 三是,不需要考虑算力,因为有整个数据中心的支撑,算力可以认为是无限的;
- 四是,也不需要操心运维,维护系统持续地平稳运行是云服务商的责任,而不再是开发者的责任。
这是不是就像从汇编语言发展到高级语言后,开发者不用再去关注寄存器、信号、中断等与机器底层相关的细节?没错儿,UC Berkeley 的论文“Cloud Programming Simplified: A Berkeley View on Serverless Computing”中,就是这样描述无服务给生产力带来的极大解放的。
与单体架构、微服务架构不同,无服务架构天生的一些特点,比如冷启动、 无状态、运行时间有限制等等,决定了它不是一种具有普适性的架构模式。软件开发的未来,不会只存在某一种“最先进的”架构风格,而是会有多种具有针对性的架构风格并存。更多详情可以查看这里,凤凰架构-周志明。
架构模式(风格)
架构模式也像设计模式一样,都是通用性,可复用的解决方案。不同的是,架构模式是针对在特定情境下软件架构上的常见问题。
在架构演进中我们就提到以下模式:
- 单体架构( Monolithic application)
- 分层架构 (Layered )
- 烟囱式架构(Information Silo Architecture)
- 微内核架构(Microkernel Architecture)
- 事件驱动架构 (Event-driven)
- SOA架构(Service-oriented)
- 微服务架构Microservices architecture
- 服务网格(Service Mesh)
- 无服务架构(Serverless computing)
在wiki中还有以下常见的模式:
- Blackboard
- Client-server (2-tier, 3-tier, n-tier, cloud computing exhibit this style)
- Component-based
- Data-centric
- Peer-to-peer (P2P)
- Pipes and filters
- Plug-ins
- Reactive architecture
- Representational state transfer (REST)
- Rule-based
- Shared nothing architecture
- Space-based architecture
更多模式设计相关可以参考下面资料:
- software-architecture-patterns ,oreilly中对上述几种常见的模式进行深入分析。
- Cloud Design Patterns ,微软云平台 Azure 上的设计模式,罗列了分布式设计的各种设计模式,对于每一个模式都有详细的说明,并有对其优缺点的讨论,以及适用场景和不适用场景的说明。
- Design patterns for container-based distributed systems,Google在容器化下的分布式架构的设计模式。
- Patterns for distributed systems, Martin Fowler 关于分布式系统的设计模式。
- Patterns of Enterprise Application Architecture,Martin Fowler专门针对企业应用架构的书写的,企业应用架构设计模式。
- Designing Data-Intensive Applications,中文译名数据密集型应用系统设计,但其实讲了很多分布式相关的设计和理论。
面向对象设计
架构设计终究是要落地的,而落地的实践,最终离不开代码,模块(组件)的组织。下面我们就来讨论下面“向对象的设计”
模型
面向对象设计目标是高内聚、低耦合,那么今天我们从这两个维度,看组件的设计原则。
组件内聚原则
组件内聚原则主要讨论哪些类应该聚合在同一个组件中,以便组件既能提供相对完整的功能,又不至于太过庞大。在具体设计中,可以遵循以下三个原则。
- 复用发布等同原则,软件复用的最小粒度应该等同于其发布的最小粒度
- 共同封闭原则,我们应该将那些会同时修改,并且为了相同目的而修改的类放到同一个组件中。
- 共同复用原则,不要强迫一个组件的用户依赖他们不需要的东西。
组件耦合原则
- 无循环依赖原则,组件依赖关系中不应该出现环
- 稳定依赖原则,组件依赖关系必须指向更稳定的方向
- 稳定抽象原则,一个组件的抽象化程度应该与其稳定性程度一致(JDBC,slf4j)
当然,上面讨论的是关于组件的,并没有考虑业务场景(模块的划分,更多的是业务场景的考虑),构建模型的难点,首先在于分离关注点,其次在于找到共性。下面我们从面向对象的概念来具体看看这两个难点。
面向对象概念
使用面向对象语言(java)写出来的代码风格就是面向对象的吗?可能未必,如果对面向对象的理解有偏差,可能会写出C语言风格的代码,例如代码里却没有体现出面向对象程序的特点,没有封装,更不用说继承和多态。所以在讨论设计之前有必要先聊聊面向对象的几个特征。
封装
理解封装
封装,是面向对象的根基。它把紧密相关的信息放在一起,形成一个单元。“面向对象”这个词是由 Alan Kay 创造的,他是 2003 年图灵奖的获得者。在他最初的构想中:
对象就是一个细胞。当细胞一点一点组织起来,就可以组成身体的各个器官,再一点一点组织起来,就构成了人体。而当你去观察人的时候,就不用再去考虑每个细胞是怎样的
封装的重点在于对象提供了哪些行为,而不是有哪些数据。理解了这一点,我们来看一个日常编程习惯,编写一个类的方法是,把这个类有哪些字段写出来,然后,生成一大堆 getter 和 setter,将这些字段的访问暴露出去。这种做法的错误就在于把数据当成了设计的核心,这一堆的 getter 和 setter,就等于把实现细节暴露了出去。
一个正确的做法应该是,我们设计一个类,先要考虑其对象应该提供哪些行为。然后,我们根据这些行为提供对应的方法,最后才是考虑实现这些方法要有哪些字段。
减少暴露接口
封装,除了要减少内部实现细节的暴露,还要减少对外接口的暴露。一个原则是最小化接口暴露。
继承
如果我们把继承理解成一种代码复用方式,更多地是站在子类的角度向上看。在客户端代码使用的时候,面对的是子类,这种继承叫实现继承:
Child object = new Child();
另一种看待继承的角度,就是从父类的角度往下看,客户端使用的时候,面对的是父类,这种继承叫接口继承:
Parent object = new Child();
其实把实现继承当作一种代码复用的方式,并不是好的方式。主要有以下两点:
- java是单继承语言,每个类只能有一个父类,一旦继承的位置被实现继承占据了,再想做接口继承就很难了。
- 实现继承通常也是一种受程序设计语言局限的思维方式,有很多程序设计语言,即使不使用继承,也有自己的代码复用方式。
组合优于继承
有一个通用的原则叫做:组合优于继承。也就是说,如果一个方案既能用组合实现,也能用继承实现,那就选择用组合实现。
通过一个例子,我们来看下组合和继承设计上的差异。我们有个字体类(Font),现在的需求是,字体能够加粗(Bold)、能够有下划线(Underline)、还要支持斜体(Italic),而且这些能力之间是任意组合的。
如果采用继承的方式,那就要有 8 个类:

而采用组合的方式,我们的字体类(Font)只要有三个独立的维度,也就是是否加粗(Bold)、是否有下划线(Underline)、是否是斜体(Italic)。这还不是终局,如果再来一种其他的要求,由 3 种要求变成 4 种,采用继承的方式,类的数量就会膨胀到 16 个类,而组合的方式只需要再增加一个维度就好。我们把一个 M*N 的问题,通过设计转变成了 M+N 的问题,复杂度的差别一望便知。
多态
多态(Polymorphism),顾名思义,一个接口,多种形态。上面讲了继承有两种,实现继承和接口继承。其中,实现继承尽可能用组合的方式替代继承。而接口继承,主要是给多态用的。运用多态需要构建出一个抽象,即找出不同事物的共同点。而寻找共同点这件事,最主要还是在分离关注点上。
在构建抽象上,接口扮演着重要的角色。
隔离变化
首先,接口将变的部分和不变的部分隔离开来,不变的部分就是接口的约定,而变的部分就是子类各自的实现。在软件开发中,对系统影响最大的就是变化。识别出变与不变,是一种很重要的能力。
定义边界
其次,接口是一个边界。无论是什么样的系统,清晰界定不同模块的职责是很关键的,而模块之间彼此通信最重要的就是通信协议。这种通信协议对应到代码层面上,就是接口。实际开发中,我们在接口中添加方法总是很随意,并没有区分实现者和使用者角色的差异,这也就导致边界的模糊,模块划分不清,彼此之间互相影响。
面向接口编程
面向对象的基本原则,面向接口编程。面向接口编程的价值就根植于多态,也正是因为有了多态,一些设计原则,比如,开闭原则、接口隔离原则才得以成立,相应地,设计模式才有了立足之本。
设计的目的
在讨论设计的目的之前,先来看看没有设计,或者糟糕的设计会带来什么样的影响。
糟糕的设计
糟糕的设计和代码有如下一些特点,这些特点共同铸造了糟糕的软件。
僵化性
代码之间耦合严重,难以改动,任何微小的改动都会引起更大范围的改动。一个看似微小的需求变更,却发现需要在很多地方修改代码。修改的成本随着时间的增长而增加。
脆弱性
比僵化性更糟糕的是脆弱性,僵化导致任何一个微小的改动都能引起更大范围的改动,而脆弱则是微小的改动容易引起莫名其妙的崩溃或者 bug,出现 bug 的地方看似与改动的地方毫无关联,或者软件进行了一个看似简单的改动,重新启动,然后就莫名其妙地崩溃了。
牢固性
牢固性是指软件无法进行快速、有效地拆分。想要复用软件的一部分功能,却无法容易地将这部分功能从其他部分中分离出来。
粘滞性
需求变更导致软件变更的时候,如果糟糕的代码变更方案比优秀的方案更容易实施,那么软件就会向糟糕的方向发展。很多软件在设计之初有着良好的设计,但是随着一次一次的需求变更,最后变得千疮百孔,趋向腐坏。
晦涩性
代码首先是给人看的,其次是给计算机执行的。如果代码晦涩难懂,必然会导致代码的维护者以设计者不期望的方式对代码进行修改,导致系统腐坏变质。把代码写简单可不容易。
软件不是一次性的,在其漫长的生命周期中会被不断修改、迭代、演化、发展。如果毫无设计,或者糟糕的设计会导致其不断腐化,而解决之道就是遵循设计原则,灵活运用各种设计模式。
设计原则
在软件设计中,有众多的原则,这里我们就来讲讲SOLID这个面向对象的设计原则。
单一职责原则(Single Responsibility Principle, SRP)
开闭原则(Open Closed Principle,OCP)
里氏替换原则(Liskov Substitution Principle,LSP)
接口隔离原则(Interface Segregation Principle,ISP)
依赖倒转原则(Dependency Inversion Principle,DIP)
下面简单讲讲这几个原则。
单一职责原则(SRP)
设计类的时候,我们应该把强相关的元素放在一个类里,而弱相关性的元素放在类的外边。保持类的高内聚性。具体设计时应该遵循这样一个设计原则:一个类,应该只有一个引起它变化的原因。
如果一个类承担的职责太多,就等于把这些职责都耦合在一起。这种耦合会导致类很脆弱:当变化发生的时候,会引起类不必要的修改,进而导致 bug 出现。职责太多,还会导致类的代码太多。
一个类太大,它就很难保证满足开闭原则,如果不得不打开类文件进行修改,大堆大堆的代码呈现在屏幕上,一不小心就会引出不必要的错误。
如何判断一个类是否违法了单一职责原则很简单,就是看这个类是否只有一个引起它变化的原因。或者日常代码解决提交冲突最多的那个类,就该引起你的注意了。
而关于拆分方法,可以从功能职责维度去做拆分(配合DDD里聚合的设计食用更佳)、也可以从处理步骤的维度去做拆分。
开闭原则(OCP)
软件实体(模块、类、函数等等)应该对扩展是开放的,对修改是关闭的。这听起来有点矛盾,不修改,怎么实现功能需求的变更。我们先来看看哪些是违法开闭原则的。
简单粗暴来看,当我们在代码中看到 else 或者 switch/case 关键字的时候,这里就要小心是否违反开闭原则了。这是因为当我们想要进行任何需求变更的时候,都必须要修改代码。同时我们需要注意,大段的 switch/case 语句是非常脆弱的,当需要增加新的类型的时候,需要非常谨慎地在这段代码中找到合适的位置,稍不小心就可能出现 bug。
设计模式中很多模式其实都是用来解决软件的扩展性问题的,也是符合开闭原则的。实践中,我们可以使用,使用策略模式(用一个Factory返回策略类,把if的条件当做参数传给Factory,就不需要if了。 或者用一个map记录<if条件变量,策略对象>,从map中获得策略,也不需要if了),适配器模式,观察者模式,模板方法模式来实现开闭原则,实现开闭原则的关键是抽象。
开闭原则可以说是软件设计原则的原则,是软件设计的核心原则,其他的设计原则更偏向技术性,具有技术性的指导意义,而开闭原则是方向性的。
里氏替换原则(LSP)
关于如何设计类的继承关系,怎样使继承不违反开闭原则,实际上有一个关于继承的设计原则,叫里氏替换原则。简单来说就是程序中,所有使用基类的地方,都应该可以用子类代替。
怎么判断违反里氏替换原则,就不得不提起经典案例, 正方形可以继承长方形吗?小马驹可以继承马吗?
一个继承设计是否违反里氏替换原则,需要在具体场景中考察。而一个重要的契约是子类不能比父类更严格。
正方形继承了长方形,但是正方形有比长方形更严格的契约,即正方形要求长和宽是一样的。因为正方形有比长方形更严格的契约,那么在使用长方形的地方,正方形因为更严格的契约而无法替换长方形。我们开头小马继承马的例子也是如此,小马比马有更严格的要求,即不能骑,那么小马继承马就是不合适的。
再来看看JDK中违反的例子
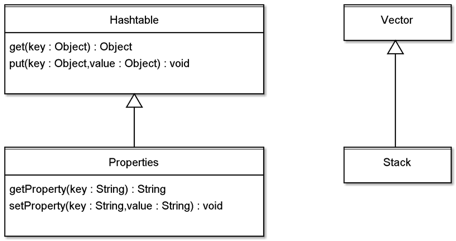
Properties 要求处理的数据类型是 String,而它的父类 Hashtable 要求处理的数据类型是 Object,子类比父类的契约更严格;Stack 是一个栈数据结构,数据只能后进先出,而它的父类 Vector 是一个线性表,子类比父类的契约更严格。
接口隔离原则(ISP)
当一个类比较大的时候,如果该类的不同调用者被迫依赖类的所有方法,就可能产生不必要的耦合。对这个类的改动也可能会影响到它的不同调用者,引起误用,导致对象被破坏,引发 bug。
使用接口隔离原则,就是定义多个接口,不同调用者依赖不同的接口,只看到自己需要的方法。而实现类则实现这些接口,通过多个接口将类内部不同的方法隔离开来。
一方面,从API开发和调用的角度来看,使用接口隔离可以以避免不必要的依赖和方法的误用。
一方面是划分职责,接口隔离原则在迭代器设计模式中的应用,在 Java5 以前,每种容器的遍历方法都不相同,在 Java5 以后,可以统一使用这种简化的遍历语法实现对容器的遍历。而实现这一特性,主要就在于 Java5 通过 Iterable 接口,将容器的遍历访问从容器的其他操作中隔离出来,使 Java 可以针对这个接口进行优化,提供更加便利、简洁、统一的语法。
依赖倒转原则(DIP)
在软件开发过程中,我们经常会使用各种编程框架。这些框架的一个特点是,当开发者使用框架开发一个应用程序时,无需在程序中调用框架的代码,就可以使用框架的功能特性。比如程序不需要调用 Spring 的代码,就可以使用 Spring 的依赖注入,MVC 这些特性,开发出低耦合、高内聚的应用代码。我们的程序更不需要调用 Tomcat 的代码,就可以监听 HTTP 协议端口,处理 HTTP 请求。
这些框架设计的核心关键点,也就是面向对象的基本设计原则之一:依赖倒置原则(好莱坞原则)。
依赖倒置原则通俗说就是,高层模块不依赖低层模块,而是都依赖抽象接口,这个抽象接口通常是由高层模块定义,低层模块实现。
通常的编程习惯中,低层模块拥有自己的接口,高层模块依赖低层模块提供的接口,比如方法层有自己的接口,策略层依赖方法层的接口;DAO 层定义自己的接口,Service 层依赖 DAO 层定义的接口。
但是按照依赖倒置原则,接口的所有权是被倒置的,也就是说,接口被高层模块定义,高层模块拥有接口,低层模块实现接口。不是高层模块依赖底层模块的接口,而是低层模块依赖高层模块的接口,从而实现依赖关系的倒置。
其他原则
合成/聚合复用原则(Composite/Aggregate Reuse Principle,CARP)
最少知识原则(Least Knowledge Principle,LKP)或者迪米特法则(Law of Demeter,LOD)
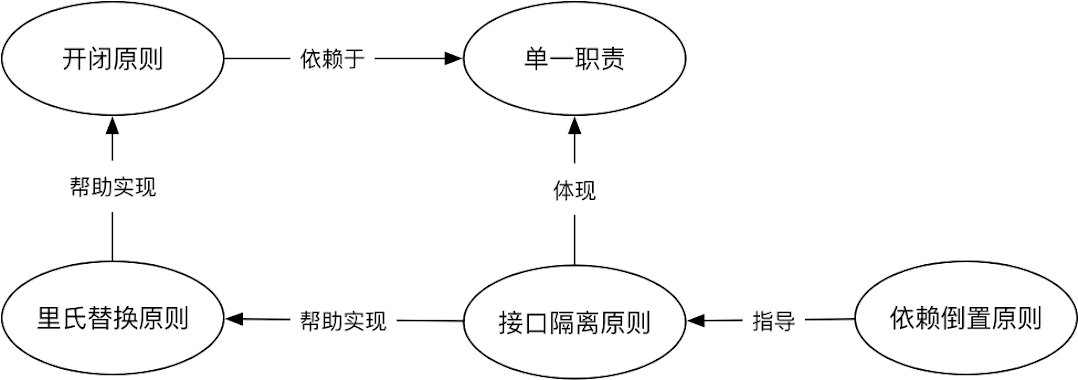
设计原则之间的关系
从整体来看,设计原则之间的关系:单一职责是所有设计原则的基础,开闭原则是设计的终极目标。里氏替换原则强调的是子类替换父类后程序运行时的正确性,它用来帮助实现开闭原则。而接口隔离原则用来帮助实现里氏替换原则,同时它也体现了单一职责。依赖倒置原则是过程式编程与OO编程的分水岭,同时它也被用来指导接口隔离原则。
图片来源
thoughtworks关于原则不错的文章:
- https://insights.thoughtworks.cn/understand-solid-principles/
- https://insights.thoughtworks.cn/what-is-solid-principle/
设计模式
所谓模式,其实就是针对的就是一些普遍存在的问题给出的解决方案。
模式这个说法起源于建筑领域,建筑师克里斯托佛·亚历山大曾把建筑中的一些模式汇集成册。结果却是墙里开花墙外香,模式这个说法却在软件行业流行了起来。
最早是 Kent Beck 和 Ward Cunningham 探索将模式这个想法应用于软件开发领域,之后,Erich Gamma 把这一思想写入了其博士论文。而真正让建筑上的模式思想成了设计模式,在软件行业得到了广泛地接受,则是在《设计模式》这本书出版之后了。这本书扩展了 Erich Gamma 的论文。四位作者 Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides 也因此名声大噪,得到了 GoF(Gang of Four,GoF) 的称呼。我们今天大部分人知道的 23 种设计模式就是从这本书来的,而困惑也是从这里开始的。
基本要素
面向对象编程的本质是多态,而设计模式的精髓是对多态的使用。设计原则大部分都是和多态有关的,不过这些设计原则更多时候是具有指导性,编程的时候还需要依赖更具体的编程设计方法,这些方法就是设计模式。
模式是可重复的解决方案,人们在编程实践中发现,有些问题是重复出现的,虽然场景各有不同,但是问题的本质是一样的,而解决这些问题的方法也是可以重复使用的。人们把这些可以重复使用的编程方法称为设计模式。
设计模式有四个基本要素:
- 模式名称(pattern name):一个助记名,它用一两个词来描述模式的问题、解决方案和效果。
- 问题(problem):描述了应该在何时使用模式。
- 解决方案(solution):描述了设计的组成成分,它们之间的相关关系以及各自的职责和协作方案。
- 效果(consequences):描述了模式应用的效果以及使用模式应该权衡的问题。
开发者很多时候会重点关注第1和第3点要素(过度关注设计模式和设计模式的实现),忽略第2和第4点要素(忽视使用设计模式的场景和目标),导致设计出来的编码逻辑可能过于复杂或者达不到预期的效果。
GOF23
分类
设计模式在粒度和抽象层次各不相同,下面是23种设计按照两个准则(目的和范围)进行分类
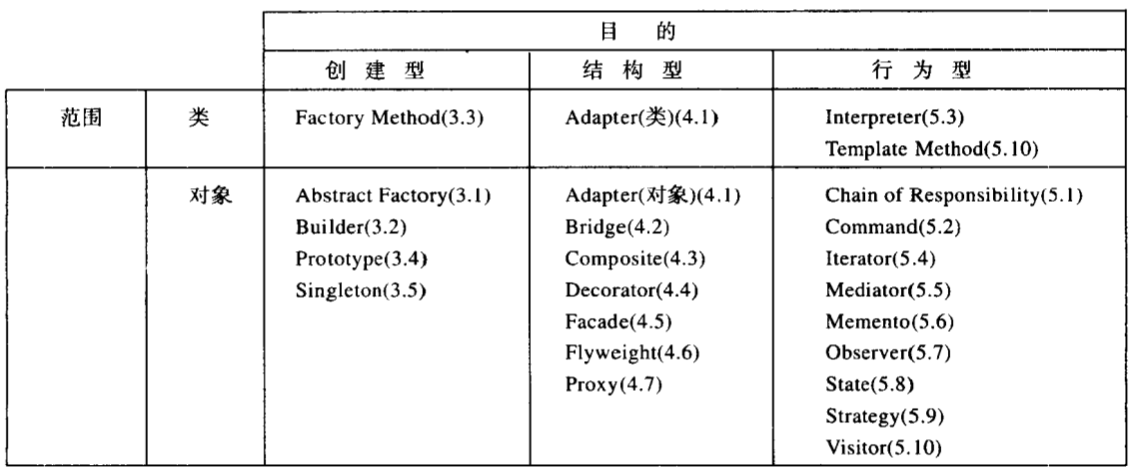
图片来源《设计模式》
第一个目的准则,可分为创建型、结构型、行为型:
- 创建型,创建型模式与对象的创建有关;
- 结构型,结构型模式处理类或对象的组合;
- 行为型,行为型模式对类或对象怎样交互和怎么样分配职责进行描述。
第二个范围准则,指定模式主要是用于类还是对象:
- 类,类模式处理类和子类之间的关系,这些关系通过继承建立,是静态的。
- 创建型类模式,将对象的部分创建工作延迟到子类
- 结构型类模式,使用继承机制来组合类
- 行为型类模式,使用继承描述算法和控制流
- 对象,对象模式处理对象间的读过哪些,这些关系在运行时刻是可以变化的,具有动态性。
- 创建型对象模式,将对象的部分创建工作延迟到另一个对象中
- 结构型对象模式,描述对象的组装方式
- 行为型对象模式,描述一组对象怎么协作完成单个对象无法完成的任务
关系
下图是描述模式之间怎么相互引用来组织设计模式的:
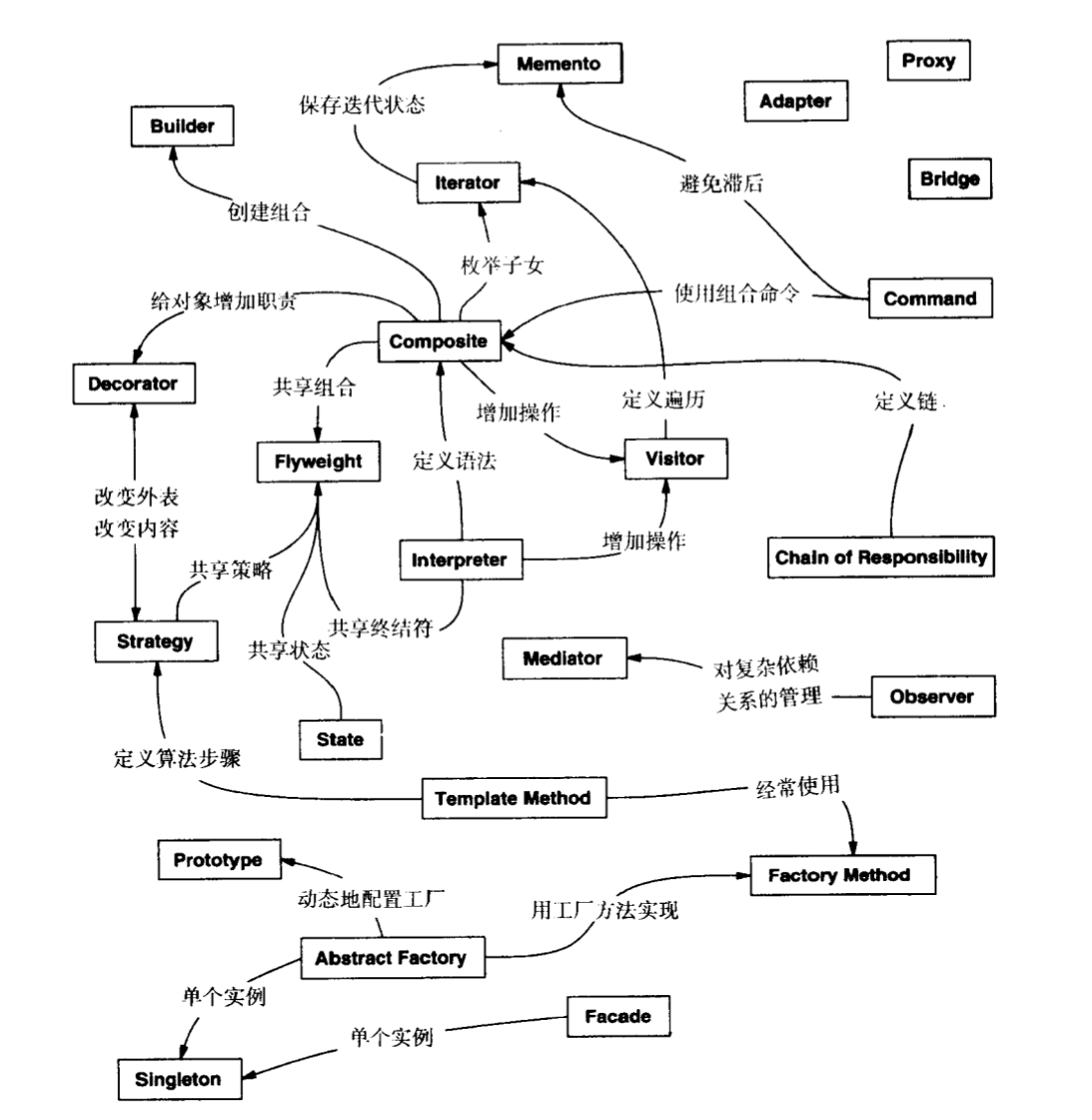
图片来源《设计模式》
学习设计模式或者是在工程中实践设计模式,必须深入到某一个特定的业务场景中去,再结合对业务场景的理解和领域模型的建立,才能体会到设计模式思想的精髓。
事实上,设计模式不仅仅包括《设计模式》这本书里讲到的 23 种设计模式,只要可重复用于解决某个问题场景的设计方案都可以被称为设计模式。
框架中的设计模式
关于框架,我们前面已经解释过了,框架是对某一类架构方案可复用的设计与实现。那么下面我们来说说如何设计、开发一个编程框架?框架应该满足哪些原则?
框架应该满足开闭原则,即面对不同应用场景,框架本身是不需要修改的,需要对修改关闭。但是各种应用功能却是可以扩展的,即对扩展开放,应用程序可以在框架的基础上扩展出各种业务功能。
同时还应该满足依赖倒置原则,即框架不应该依赖应用程序,因为开发框架的时候,应用程序还没有呢。应用程序也不应该依赖框架,这样应用程序可以灵活更换框架。框架和应用程序应该都依赖抽象
编程框架与应用程序、设计模式、设计原则之间的关系如下图所示。

下面我们从设计模式的角度来看框架,都运用了哪些设计模式,学习它们的最佳实践。
Spring
spring框架有大量设计模式的运用,这里简单列举几个
- 工厂模式:通过BeanFactory和ApplicationContext来创建对象
- 单例模式:Spring Bean默认位单例模式
- 策略模式:例如ReSource的实现类,针对不同的资源文件,实现了不同方式的资源获取策略
- 代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术
- 模板方法:以Template结尾的,例如RestTemplate、JmsTemplate、JpaTemplate
- 适配器模式:SpringAOP的增强或通知(Adive)使用到了适配器模式
- 观察者模式:Spring事件驱动模式
Mybatis
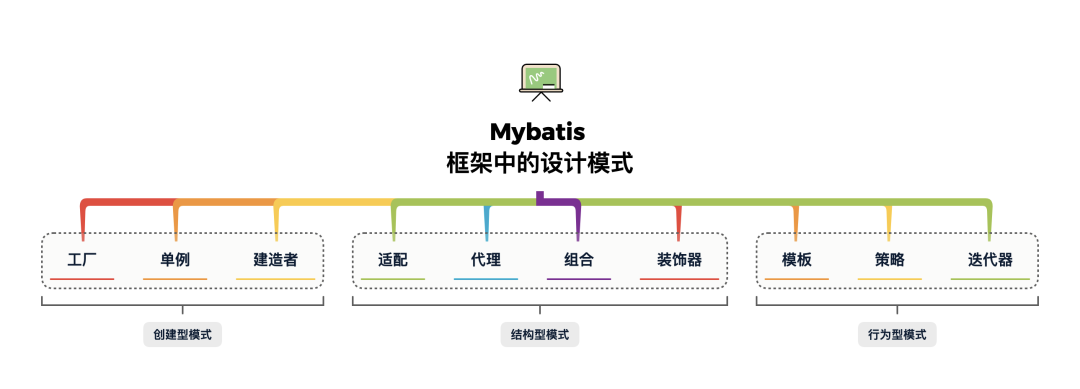
图片来源
其他更多框架的设计模式,例如tomcat 也可以参考 深入分析Java Web技术内幕(修订版)中也有讨论。
使用场景
什么时候使用?为什么会有过分设计和设计不足? 这里的区分在于使用场景,我们在前面基本要素的也提到过这一点。
设计不足
如果已经发生了需求变更,但是你却没有用灵活的设计方法去应对,而是通过硬编码的方式在既有代码上打补丁,那么这就是设计不足。 设计模式的使用难点,在于判断模式要解决的是否是同一个问题,这也是为什么我们提倡通过重构获得模式:当问题明显出现的时候(以坏味道的形式),那么最难的一步其实你已经解决了
过分设计
如果你为需求变更而进行了设计,但是预期中的需求变更却从来没有发生过,那么你的设计就属于设计过度;
Avoid Over Engineering ,有时候,我们会过度设计我们的系统,过度设计会把我们带到另外一个复杂度上,所以,我们需要一些工程上的平衡。这篇文章是一篇非常不错地告诉你什么是过度设计的文章。
具体场景的权衡
前面我们都提到了违反原则会导致的问题,那是不是设计就一定不能违反原则,违反原则都是错误的?我们来看个具体的例子,在Servlet中,HttpServlet 通过继承 GenericServlet 实现了 Servlet 接口,并在自己的 service 方法中,针对不同的 HTTP 请求类型调用相应的方法,HttpServlet 的 service 方法就是一个模板方法。
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException
{
String method = req.getMethod();
if (method.equals(METHOD_GET)) {
doGet(req, resp);
} else if (method.equals(METHOD_HEAD)) {
long lastModified = getLastModified(req);
maybeSetLastModified(resp, lastModified);
doHead(req, resp);
} else if ...
service里方法不停的if/else 是不是违反的我们的开闭原则?
显然是违反开闭原则的。但是这里如果用策略模式消除这些if else,可能会导致开发者需要继承不同的类处理不同的HTTP请求,提高开发者的学习和使用成本。 是否要遵循原则,要看具体场景进行权衡。HTTP协议中的请求方法诞生以来都没有被修改过,所以写死也是一个办法。
相关资料
- 美团的实践,设计模式在外卖营销业务中的实践
- 关于设计模式,挺有意思的网站
领域驱动设计
DDD是什么
领域驱动设计(Domain Driven Design,DDD)是 Eric Evans 在《领域驱动设计》中提出的从系统分析到软件建模的一套方法论。它要解决什么问题呢?就是将业务概念和业务规则转换成软件系统中概念和规则,从而降低或隐藏业务复杂性,使系统具有更好的扩展性,以应对复杂多变的现实业务问题。我们前面讨论的设计,更多的是从系统和代码模块 结构的层面考虑,而领域驱动设计是设计中关于业务方面的补充。
关于设计模式和领域模型驱动设计的关系,站在业务建模的立场上,DDD的模式解决的是如何进行领域建模。而站在代码实践的立场上,设计模式主要关注于代码的设计与实现,本质上都是“模式”。
使用DDD的目的
在对抗软件架构腐烂的时候,我们可能会想到敏捷实践中的重构(重构中使用设计模式)、测试驱动设计及持续集成可以对付各种混乱问题
- 重构,保持行为不变的代码改善清除了不协调的局部设计
- 测试驱动设计,确保对系统的更改不会导致系统丢失或破坏现有功能
- 持续集成,则为团队提供了同一代码库
为什么我们有了这些方式,还需要使用DDD呢?
上述问题在于我们解决了设计到代码之间的重构,但提炼出来的设计模型,并不具有实际的业务含义,这就导致在开发新需求时,并不能很自然地将业务问题映射到该设计模型。设计似乎变成了重构者的自娱自乐,代码继续腐败,重新重构……无休止的循环。
用DDD进行业务建模,则可以很好地解决领域模型到设计模型的同步、演化,最后再将反映了领域的设计模型转为实际的代码。
而业务建模的难点有两个:清晰地定义业务问题,并让所有干系人都接受你对业务问题的定义;在特定架构的约束下,将模型实现出来。
统一语言
通用语言,就是在业务人员和开发人员之间建立起的一套共有的语言。统一语言可以包含以下内容:
- 源自领域模型的概念与逻辑;
- 界限上下文(Bounded Context);
- 系统隐喻;
- 职责的分层;
- 模式(patterns)与惯用法。
虽然在理想中,我们希望直接使用模型作为统一语言。但从实际出发,直接使用模型的效果并不好。主要是两点:模型将业务维度隐藏了,对业务方显得不够直观;对于未提取的知识,超出了模型的表达能力。因而统一语言是非常必要的。
怎么建立统一语言
至于如何建立统一语言,一般会使用事件风暴(Event Storming),主要分为三步:
- 第一步就是把领域事件识别出来,这个系统有哪些是人们关心的结果。有了领域事件,下面一个问题是,这些事件是如何产生的,它必然会是某个动作的结果。
- 第二步就是找出这些动作,也就是引发领域事件的命令。比如:产品已上架是由产品上架这个动作引发的,而订单已下就是由下单这个命令引发的。
- 第三步就是找出与事件和命令相关的实体或聚合,比如,产品上架就需要有个产品(Product),下单就需要有订单(Order)。
模型
模型在领域驱动设计中,其实主要有三个用途:
- 通过模型反映软件实现(Implementation)的结构;
- 以模型为基础形成团队的统一语言(Ubiquitous Language);
- 把模型作为精粹的知识,以用于传递。
在业务系统中,构造一种专用的模型(领域模型),将相关的业务流程与功能转化成模型的行为,能避免开发人员与业务方的认知差异,这一理念的转变开始于面向对象技术的出现,而最终的完成,则是以行业对 DDD 的采纳作为标志的。
知识消化(原则)
在 DDD 中,Eric Evans 提倡了一种叫做知识消化(Knowledge Crunching)的方法帮助我们去提炼领域模型。
知识消化法具体来说有五个步骤,分别是:
- 关联模型与软件实现;
- 基于模型提取统一语言;
- 开发富含知识的模型;
- 精炼模型;
- 头脑风暴与试验。
我们可以简单总结为 “两关联一循环”,其中“两关联”对应的是前两步,”一循环“对应的是后面三步
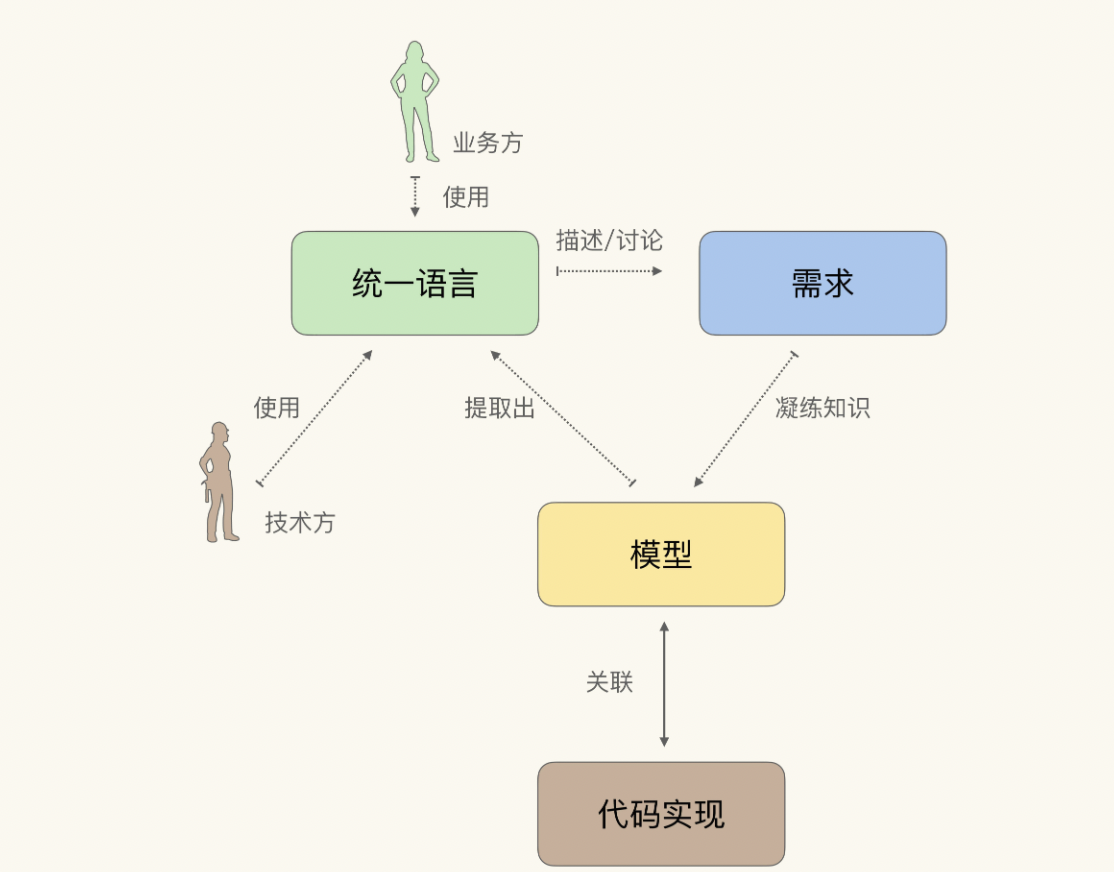
“两关联”
- 模型与软件实现关联;关联模型与软件实现(富含知识的模型、通过聚合关系表达业务概念、修改模型就是修改代码),是知识消化可以顺利进行的前提与基础
- 统一语言与模型关联;则会将业务方变成模型的使用者。
“一循环”
提炼知识的循环。通过统一语言讨论需求;发现模型中的缺失或者不恰当的概念,精炼模型以反映业务的实践情况;对模型的修改引发了统一语言的改变,再以试验和头脑风暴的态度,使用新的语言以验证模型的准确。
如此循环往复,不断完善模型与统一语言。因其整体流程与重构(Refactoring)类似,也有人称之为重构循环。知识消化是一种迭代改进试错法,它并不追求模型的好坏,而是通过迭代反馈的方式逐渐提高模型的有效性。
建立模型(模式)
我们有了通用语言,知道了模型应该怎么迭代循环,但面对这么多的业务模型,该如何组织呢?怎样补全欠缺的模型,使之成为一个可以落地的方案呢?也正是因为在通常情况下,业务模型数量众多,所以在 DDD 的过程中,我们将设计分成了两个阶段:战略设计(Strategic Design)和战术设计(Tactical Design)
战略设计
战略设计是高层设计,是指将系统拆分成不同的领域。而领域驱动设计,核心的概念就是领域,也就是说,它给了我们一个拆分系统的新视角:按业务领域拆分。
领域(domain)
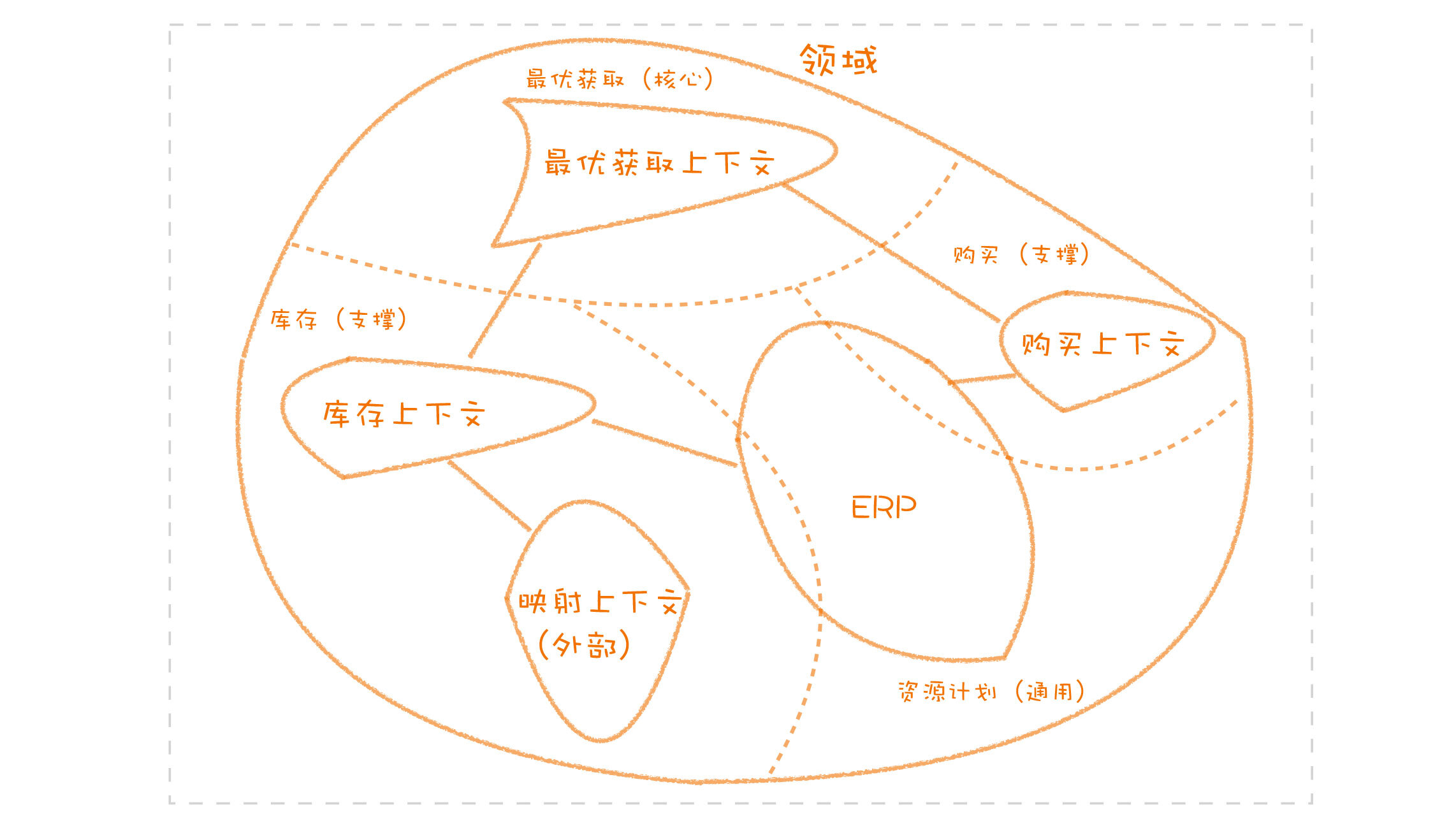
领域就是用来确定范围的,范围即边界,这也是 DDD 在设计中不断强调边界的原因。领域可以进一步划分为子领域。我们把划分出来的多个子领域称为子域,每个子域对应一个更小的问题域或更小的业务范围。
比如,我把一个电商系统拆分成产品域、订单域、支付域、物流域等。拆分成领域之后,我们识别出来的各种业务对象就会归结到各个领域之中。拆分成多个领域后,但并非每个子域都一样重要。所以,我们还要把划分出来的子域再做一下区分,分成核心域(Core Domain)、支撑域(Supporting Subdomain)和通用域(Generic Subdomain)。
- 核心域,整个系统最重要的部分,如何识别(为什么这个系统值得写,为什么不直接买一个,为什么不外包),例如在电商中的黄金流程。
- 支撑域,非核心竞争力的子域,但是不得不做。例如排行榜功能。
- 通用域,则是你需要用到的通用系统,第三方服务。例如认证、权限、发送短信等等
我们之所以要区分不同的子域,关键的原因就在于,我们可以决定不同的投资策略。核心域要全力投入,支撑域次之,通用域甚至可以花钱买服务。
切分出来的子域,怎样去落实到代码上呢?首先要解决的就是这些子域如何组织的问题,这就引出了领域驱动设计中的一个重要的概念,限界上下文。
限界上下文(Bounded Context)
限界上下文,顾名思义,它形成了一个边界,一个限定了通用语言自由使用的边界,一旦出界,含义便无法保证。比如,同样是说“订单”,如果不加限制,你很难区分它是用在哪种场景之下。而一旦定义了限界上下文,那交易上下文的“订单”和物流上下文的“订单”肯定是不同的。原因就在于,订单这个说法,在不同的边界内,含义是不一样的。
注意,子域和限界上下文不一定是一一对应的,可能在一个限界上下文中包含了多个子域,也可能在一个子域横跨了多个限界上下文。
同时微服务的一个难点如何划分服务边界,而限界上下文的出现刚好与微服务的理念契合,每个限界上下文都可以成为一个独立的服务。
有了对限界上下文的理解,我们就可以把整个业务分解到不同的限界上下文中,那么上下之间是怎么交互的,就是上下文映射图需要解决的事情了。
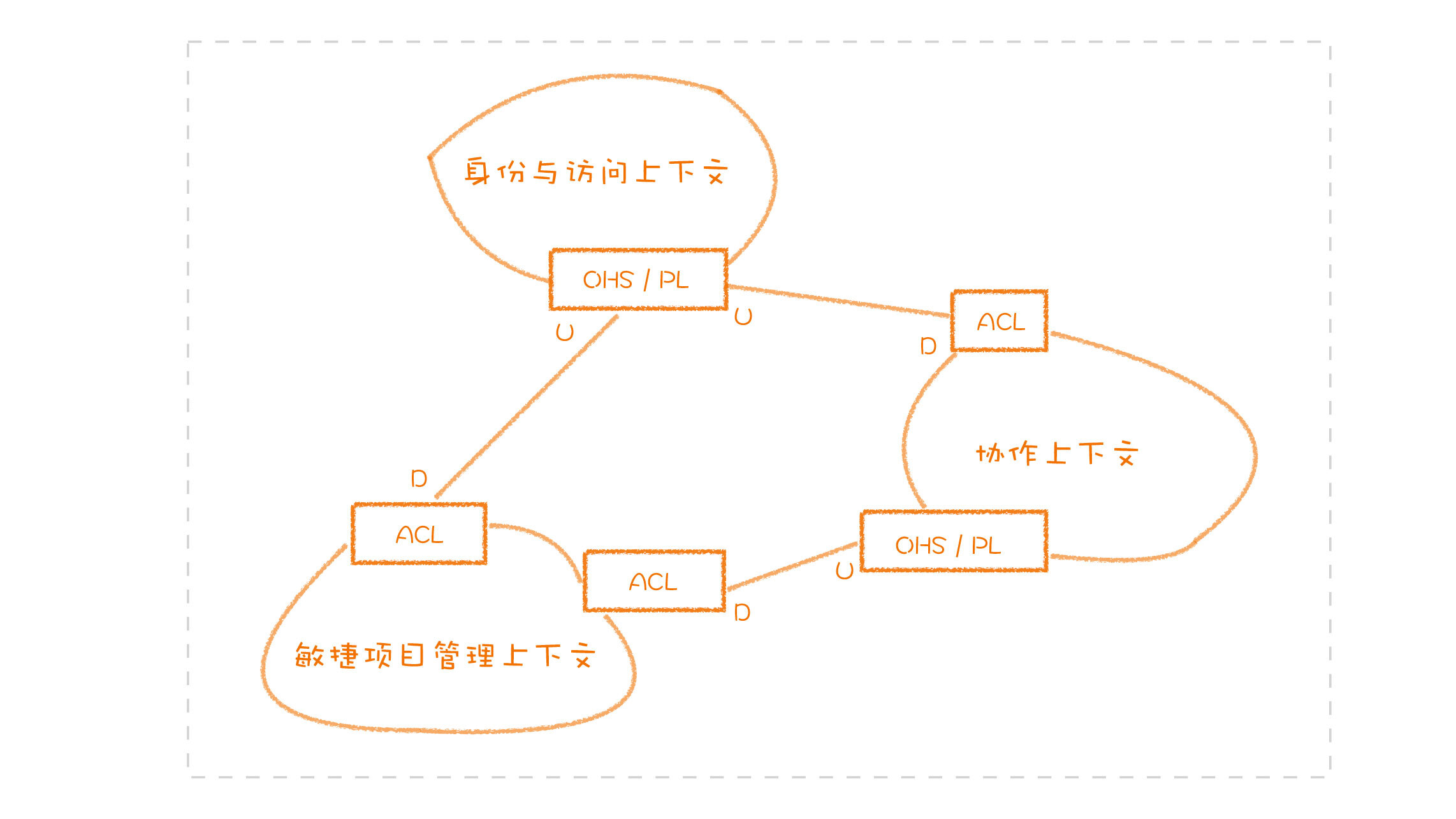
上下文映射图(Context Map)
上下文映射图,一种描述方式,将不同限界上下文之间交互的方式描述出来。DDD 给我们提供如下方式:
- 合作关系(Partnership)
- 共享内核(Shared Kernel)
- 客户 - 供应商(Customer-Supplier)
- 跟随者(Conformist)
- 防腐层(Anticorruption Layer),最具防御性的一种关系,在外部模型和内部模型之间建立起一个翻译层,将外部模型转化为内部模型。
- 开放主机服务(Open Host Service)
- 发布语言(Published Language)
- 各行其道(Separate Ways)
- 大泥球(Big Ball of Mud)
当我们知道了不同的限界上下文之间采用哪种交互方式之后,不同的交互方式就可以落地为不同的协议。现在最常用的几种协议有 REST API、RPC 或是消息队列,我们可以根据实际情况进行选择。
在我们定义好不同的限界上下文,将它们之间的交互呈现出来之后,我们就得到了一张上下文映射图。上下文映射图是可以帮助我们理解系统的各个部分之间,是怎样进行交互的,帮我们建立一个全局性的认知。
战术设计
战术设计是低层设计,也就是如何具体地组织不同的业务模型。在这个层次上,DDD 给我们提供了一些标准的做法供我们参考。主要有以下步骤
- 梳理有模型哪些角色,比如,哪种模型应该设计成实体,哪些应该设计成值对象。我们还要考虑模型之间是什么样的关系,
- 梳理模型角色关系,比如,哪些模型要一起使用,可以成为一个聚合。
- 梳理模型互动(动作),接下来,我们还需要考虑这些模型从哪来、怎样演变,DDD 同样为我们提供了一些标准的设计概念,比如仓库、服务等等。
角色:实体、值对象
我们在战术设计中,首先要识别的模型角色就是实体和值对象。
什么是实体呢?实体(Entity)指的是能够通过唯一标识符标识出来的对象。再业务处理中,有一类对象会有一定的生命周期,在它的生命周期内一些属性可能会有变化。例如电商平台上的订单,它的状态(已下单、已付款、已发货)根据流程的进行会发生流转,但这个订单始终是这个订单,我们根据唯一标志符去修改它的属性。
还有一类对象称为值对象,它就表示一个值。比如,订单地址,它是由省、市、区和具体住址组成。它同实体的差别在于,它没有标识符,它是不可变的。我们为什么要将对象分为实体和值对象?其实主要是为了分出值对象,也就是把变的对象和不变的对象区分开。
在传统的做法中,找出实体是你一定会做的一件事,而在不同的模型中,区分出值对象是我们通常欠缺的考虑。比如,很多人会用一个字符串表示电话号码,会用一个 double 类型表示价格,而这些东西其实都应该是一个值对象。因为手机号是有固话、区号、前缀的概念的,而价格其实要有精度的限制,计算时要有自己的计算规则。如果不用一个类将它封装起来,这种行为就将散落在代码的各处,变得难以维护。
但是要注意一点是实体和值对象是可以相互转换的,例如有些场景中,地址会被某一实体引用,它只承担描述实体的作用,并且它的值只能整体替换,这时候你就可以将地址设计为值对象,比如收货地址。而在某些业务场景中,地址会被经常修改,地址是作为一个独立对象存在的,这时候它应该设计为实体,比如行政区划中的地址信息维护。
简单来说,它们的特点如下:
实体的特点:有 ID 标识,通过 ID 判断相等性,ID 在聚合内唯一即可。状态可变,它依附于聚合根,其生命周期由聚合根管理。实体一般会持久化,但与数据库持久化对象不一定是一对一的关系。实体可以引用聚合内的聚合根、实体和值对象。
值对象的特点:无 ID,不可变,无生命周期,用完即扔。值对象之间通过属性值判断相等性。它的核心本质是值,是一组概念完整的属性组成的集合,用于描述实体的状态和特征。值对象尽量只引用值对象。
关系:聚合和聚合根
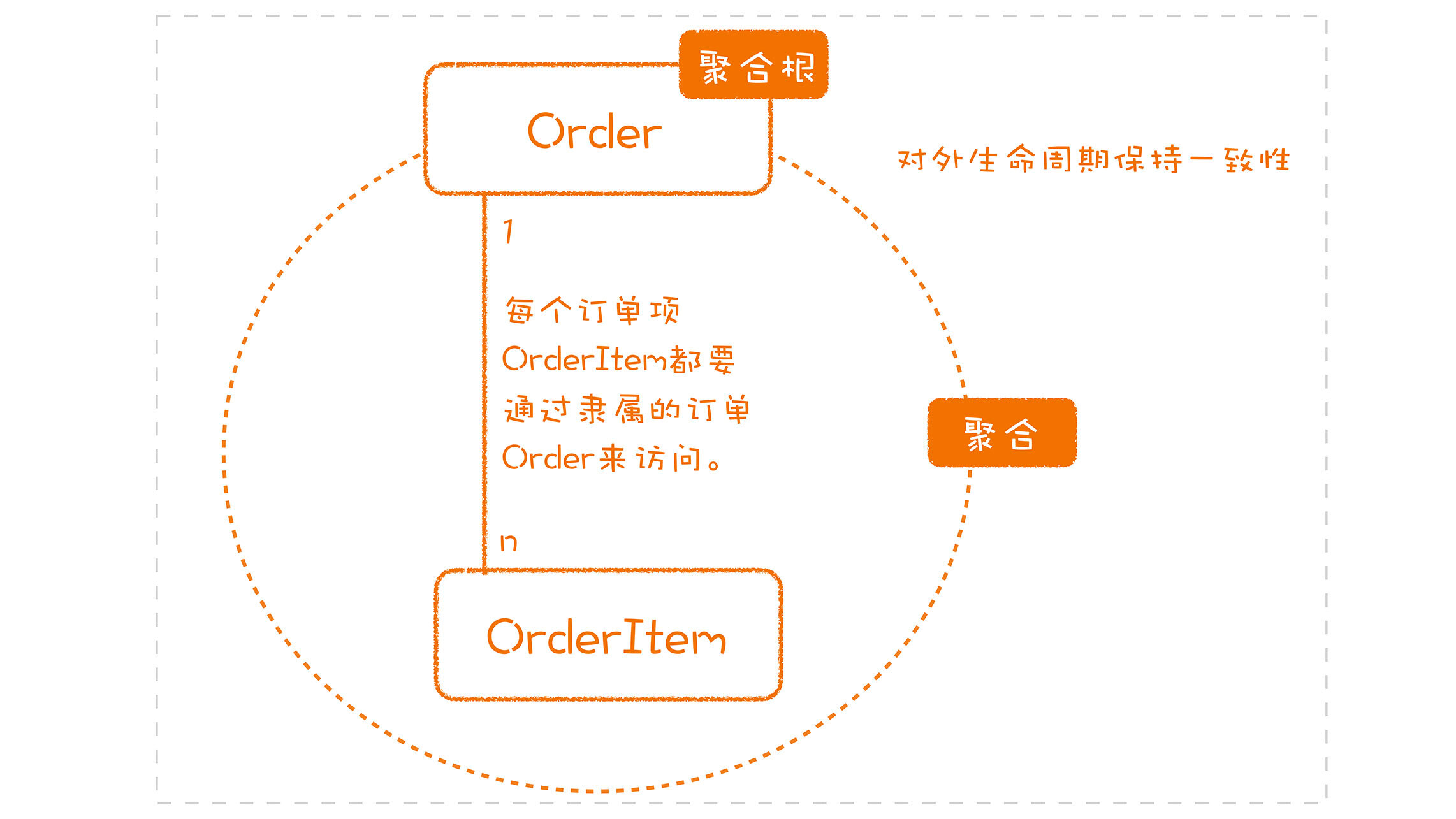
选定了角色之后,接下来,我们就该考虑它们的关系了。战术设计就给了我们这样一个思考的维度:聚合
聚合(Aggregate)就是多个实体或值对象的组合,这些对象是什么关系呢?你可以理解为它们要同生共死。比如,一个订单里有很多个订单项,如果这个订单作废了,这些订单项也就没用了。所以,我们基本上可以把订单和订单项看成一个单元,订单和订单项就是一个聚合。既然它们是一个整体,这些对象要一起操作,那么聚合要保证事务(Transaction)一致也就不难理解了。
怎么设计聚合,《实现领域驱动设计》一书中对聚合设计原则的描述:
- 在一致性边界内建模真正的不变条件,聚合用来封装真正的不变性,而不是简单地将对象组合在一起
- 设计小聚合,如果聚合设计得过大,聚合会因为包含过多的实体,导致实体之间的管理过于复杂
- 通过唯一标识引用其它聚合,聚合之间是通过关联外部聚合根 ID 的方式引用,而不是直接对象引用的方式
- 在边界之外使用最终一致性,聚合内数据强一致性,而聚合之间数据最终一致性。在一次事务中,最多只能更改一个聚合的状态
- 通过应用层实现跨聚合的服务调用,应避免跨聚合的领域服务调用和跨聚合的数据库表关联
一个聚合里可以包含很多个对象,每个对象里还可以继续包含其它的对象,就像一棵大树一层层展开。但重点是,这是一棵树,所以,它只能有一个树根,这个根就是聚合根。
聚合根(Aggregate Root),就是从外部访问这个聚合的起点。我还以上面的订单和订单项为例,在订单和订单项组成的这个聚合里,订单就是聚合根。因为你想访问它们,就要从订单入手,你要通过订单号找到订单,然后,把相关的订单项也一并拿出来。
简单来说,它们的特点如下
聚合的特点:高内聚、低耦合,它是领域模型中最底层的边界。
聚合根的特点:聚合根是实体,有实体的特点,具有全局唯一标识,有独立的生命周期。一个聚合只有一个聚合根,聚合根在聚合内对实体和值对象采用直接对象引用的方式进行组织和协调,聚合根与聚合根之间通过 ID 关联的方式实现聚合之间的协同。
互动:工厂、仓库、领域服务、应用服务
角色和关系有了,现在就来看看这些角色都有什么动作。事件风暴里会识别出事件和动作,动作的结果会产生出各种事件,也就是领域事件,领域事件相当于记录了业务过程中最重要的事情。 我们前面提到了实体或值对象上会有行为动作,那除了这两个还有其他的动作吗?
在战术设计中,领域服务(Domain Service)就是一种动作,它操作的目标是领域对象(聚合根)。通常,我们的动作应该放在实体或值对象,但总会有一些动作不适合放在这些对象上面,比如,要在两个账户之间转账,这个操作牵扯到两个账户,肯定不能放到一个实体类中。这样的动作就可以放到领域服务中。
还有一类动作也比较特殊,就是创建对象的动作,这一类的动作也要放在领域服务上,这种动作对应的就是工厂(Factory)。
对于这些领域对象,无论是创建,还是修改,我们都需要有一个地方把变更的结果保存下来,而承担这个职责的就是仓库(Repository)。
当我们把领域服务构建起来之后,核心的业务逻辑基本就成型了,这时还需要应用服务(Application Service)。应用服务可以扮演协调者的角色,协调不同的领域对象、领域服务等完成客户端所要求的各种业务动作。一般来说,一些与业务逻辑无关的内容都会放到应用服务中完成,比如,监控、身份认证等等。
应用服务和领域服务之间最大的区别就在于,领域服务包含业务逻辑,而应用服务不包含。
DDD架构
分层架构
从下图我们可以很直观的看到,DDD的架构和传统三层架构主要区别在于将原来的业务逻辑层,拆分为应用层和领域层。
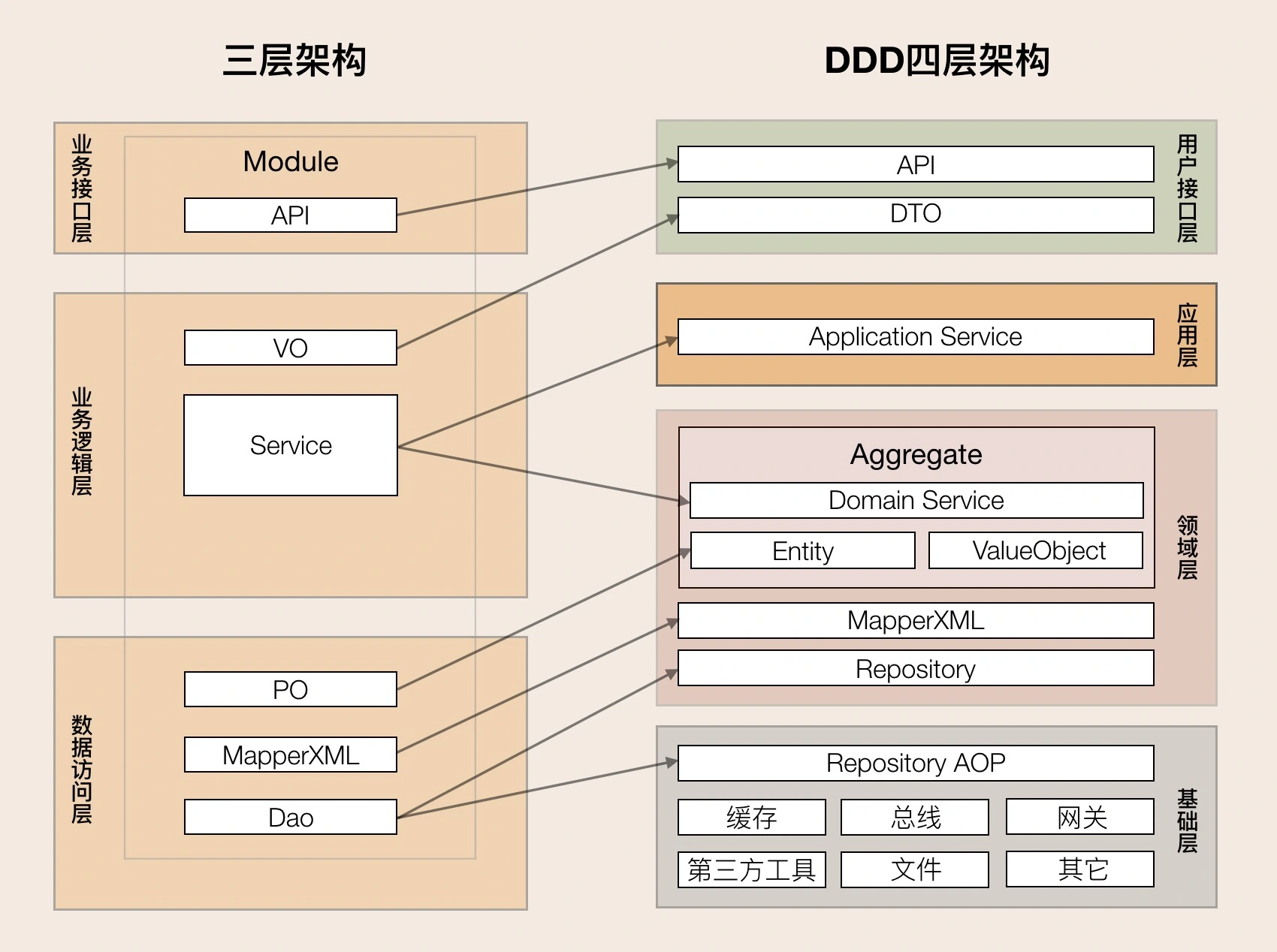
那 DDD 各层的主要职责是什么呢?
1.用户接口层
用户接口层负责向用户显示信息和解释用户指令。这里的用户可能是:用户、程序、自动化测试和批处理脚本等等。
2.应用层
我们前面提到的应用服务(Application Service)。它是一个协调者的角色,不应该有业务规则或逻辑,它可以协调多个聚合的服务和领域对象完成服务编排和组合,协作完成业务操作。不要将本该放在领域层的业务逻辑放到应用层中实现。因为庞大的应用层会使领域模型失焦,时间一长你的微服务就会演化为传统的三层架构,业务逻辑会变得混乱。
3.领域层
领域层的作用是实现企业核心业务逻辑,通过各种校验手段保证业务的正确性。领域层主要体现领域模型的业务能力,它用来表达业务概念、业务状态和业务规则。
领域层包含聚合根、实体、值对象、领域服务等领域模型中的领域对象。
4.基础层
基础层是贯穿所有层的,它的作用就是为其它各层提供通用的技术和基础服务,包括第三方工具、驱动、消息中间件、网关、文件、缓存以及数据库等。比较常见的功能还是提供数据库持久化。
分层架构的依赖原则
领域驱动设计使用分层架构,主要是因为各层的需求变化速率(Pace of Changing)不同。分层架构对变化传播的控制,是通过层与层之间的依赖关系实现的,因为下层的修改会波及到上层。我们希望通过层来控制变化的传播,只要所有层都单向依赖比自己更稳定的层,更易变依赖不易改变的,那么变化就不会扩散了。
那我们来看下领域驱动的分层是否符合这个原则
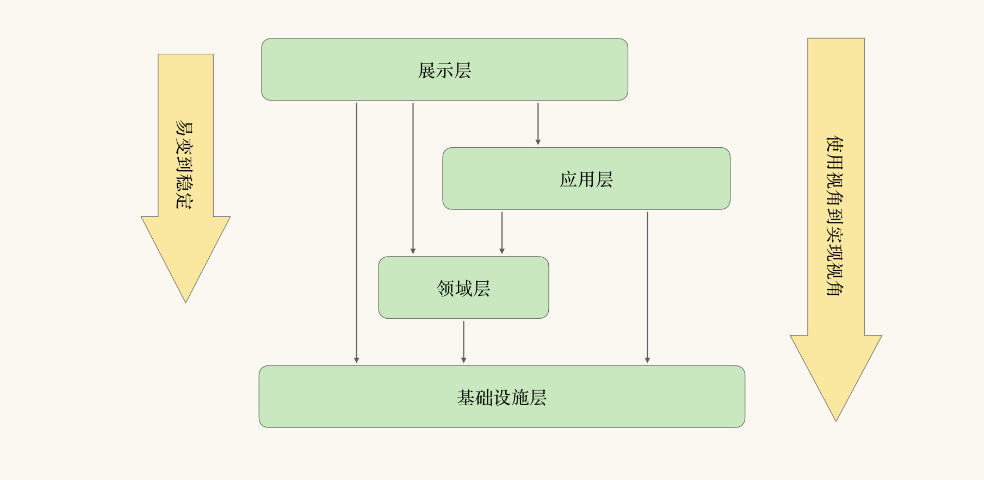
这张图通过依赖关系表示了每一层的变化速率:展示层最易变,其次是应用层,然后是领域层,最后是基础设施层。那实际情况是这样吗?
- 展现层的逻辑,的确是最容易改变的 ,新的交互模式,不同的视觉模版,都会带来展现层逻辑的改变。
- 应用层的逻辑,会随着业务流程以及功能点的变化而改变,比如流程的重组与优化、新功能点的引入,都会改变应用层的逻辑。
- 领域层是核心领域概念的提取,已经存在的领域概念和核心逻辑不会改变,在软件系统有限的生命周期内,我们可以认为领域层应该是不变的。
- 基础设施层的逻辑由所选择的技术栈决定,更改技术组件、替换所使用的框架,都会改变基础设施层的逻辑,例如基础设施层还可能存在不可预知的突变。如果我们历数过往的诸多思潮,NoSQL(Not Only SQL)、大数据(Big Data)、云计算(Cloud Computing)等等,都为基础设施层带来过未曾预期的突变。
基础设施层和领域层谁更稳定?
显然,跟领域层相比,基础设施层就不够稳定。这就违背了分层架构的依赖原则。那么解决这个依赖问题的方法是什么呢,其实DDD 的分层架构是在在不断发展,从最早是传统的四层架构,到后来通过依赖倒置实现了各层对基础层的解耦;
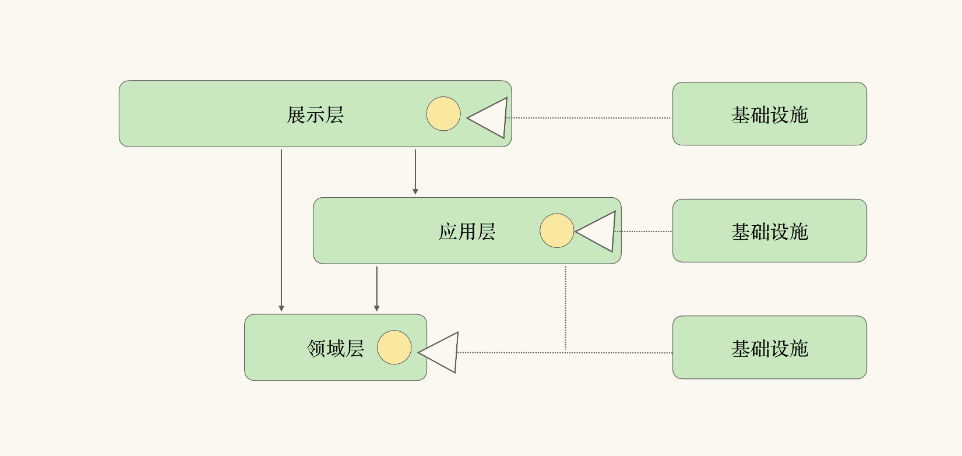
我们可以将基础设施,看作对不同的层的扩展,在每一层中留有能力接口,基础设施则作为这些能力接口的供应商(Capability Provider),参与层内、层间的交互。那么这样的架构,无论从变化的频率还是使用实现关系上就形成了统一。除此之外,我们还解决了分层架构里的另一个难题:层与层之间是单向依赖关系,那么如果需要上一层参与下一层的交互与逻辑,层与层之间就会形成双向依赖关系。
其他架构
DDD的其他架构,常见的架构有整洁架构(洋葱架构)、六边形架构(端口适配器架构)、命令查询职责分离架构(CQRS,Command Query Responsibility Segregation)。
其实这些架构的是为了分离关注点,其中清洁架构和六边形架构是将业务与技术相分离,而CQRS则是将业务领域分离为查询和命令两种方式。
另外还有一种事件溯源架构(Event sourcing),Martin Fowler在2005年的博客中提及了“Event Sourcing”这个词语,他将事件描述为一个应用的一系列状态改变,这一系列事件能够捕获用来重建当前状态的一切事实真相。他认为事件是不可变的,事件日志是一种只会不断追加(append-only)的存储。不存储当前状态,而是通过事件来计算。
DDD的学习资料
- Vaughn Vernon的《实现领域驱动设计》和《领域驱动设计精粹》
- 极客时间的《如何落地业务建模》、《DDD实战课》
- 国内 JDON的《复杂软件设计之道》《解构领域驱动设计》也可以作为补充
- 美团的领域驱动设计在互联网业务开发中的实践 也挺不错的
总结
最后,让我们一起来回顾下,首先一开始我们给出的是设计相关的概念,设计出现的原因,阐述模型与设计的关系,以及怎么建立模型,有什么指导原则,对一些重复的问题都提取了什么样的解决方案,有什么模式。
接着我们先从架构设计入手,从宏观的角度看待设计,介绍了怎么通过架构图去表达我们的系统,架构设计的目的,怎么去解决复杂度,复杂度是怎么产生的,以及架构设计应该遵循原则,同时也通过架构发展的历史,架构模式、风格应该是会有多种具有针对性的架构风格并存。
如果说架构设计是宏观的设计,那么微观设计就是,具体到代码的实现,怎么组织代码的结构,具体的落地实践。这里我们提到了面向对象的设计应该高耦合、低内聚,而怎么实现,关键在于应该遵循SOLID 的原则,这些原则的核心观念也就是分离关注点,引入中间人,同时也对设计模式分类,使用场景做了相关讨论。
而面向对象的设计在实际的使用中,会存在贫血模型的情况,针对这种的缺陷,我们使用领域驱动设计进行补充,加入了业务方面的考量。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 951488791@qq.com